 Мы в MAX
Мы в MAX 
Всё для быстрого старта в email: блочный редактор, 200 шаблонов, ИИ-помощник.
Промокод FB26K даёт скидку 99% на первый месяц тарифа «Лайт» или «Стандарт». До 28 февраля включительно.
Что внутри ChatGPT, Midjourney, Gemini и других популярных ИИ-сервисов?

Каждый год ведущие компании OpenAI, Google, Anthropic, Alibaba и другие представляют новые модели нейросетей и их версии. GPT-4 сменяет GPT-4.5, вместо Gemini Pro все обсуждают Flash, а Claude с каждой итерацией становится точнее и «разумнее». Но что вообще стоит за этими названиями? Почему одни модели умеют писать код, другие — создавать изображения, а третьи — распознавать голос? Разбираемся в статье.
Важно разграничивать между собой три понятия: нейросеть, модель нейросети и версия модели, ведь их довольно часто путают между собой.
Модель нейросети — это конкретный инструмент, который уже прошел обучение и может решить определенную задачу: сгенерировать текст, распознать лицо, перевести фразу или, например, сымитировать голос. Например, Midjourney, Claude, Gemini.

Инженер по машинному обучению (NLP) в центре анализа данных ВАВТ
Нейросеть (в данном контексте) — это подход к обучению модели и ее архитектура. То есть способ, по которому устроен алгоритм: слои «искусственных нейронов», связи между ними и способы обработки информации.
Модель нейросети — это обученная нейросеть, в которой закреплены знания, полученные на этапе обучения. Эти знания хранятся в виде числовых параметров — именно они помогают модели распознавать, анализировать и генерировать нужные ответы.
Когда вы видите обозначения вроде GPT-3.5, GPT-4, Claude 3, Midjourney v6 — это уже версии модели. Они обозначают новое поколение продукта и говорят об изменениях. Например, у Claude есть модель Sonnet и версии 3.5 и 3.7. Их отличие — в умственных способностях, скорости решения задач и возможности к рассуждению.
Разработчики создают модели нейросетей под разные задачи, с разной мощностью, архитектурой и уровнем «интеллекта». Ниже — ключевые параметры, которые определяют, на что способна конкретная модель и где она будет эффективна.
Архитектура — структура модели. То, как устроены связи между нейронами и каким образом данные проходят через модель. Именно архитектура определяет, каким типом задач нейросеть будет заниматься и как она будет это делать.
Выделяют несколько типов архитектур:
Полносвязные (или многослойные персептроны). Это базовый тип нейросети. Каждый нейрон связан со всеми нейронами следующего слоя. Используется в простых задачах: предсказать число, определить категорию.
Сверточные нейросети (CNN, Convolutional Neural Networks). Они отлично видят и распознают изображения.
Рекуррентные нейросети (RNN, Recurrent Neural Networks). Умеют работать с последовательностями — текстами, аудио, временными рядами. У них есть «память» о предыдущих шагах. Однако сегодня их почти вытеснили более продвинутые архитектуры.
Автокодировщики и их производные (Autoencoders, VAE, GAN, Diffusion). Архитектуры, основанные на принципе кодирования и декодирования информации. Сначала данные сжимаются до компактного представления (кодируются), затем восстанавливаются обратно (декодируются). Такие модели используются для восстановления изображений, сжатия данных, генерации новых объектов и удаления шумов. По подобной архитектуре работают генераторы изображений Midjourney и Stable Diffusion.

Трансформеры (Transformers). Современные суперзвезды мира ИИ. Их используют для генерации текстов, кода и даже изображений. Модели всем известного ChatGPT, начиная с GPT-3, построены на основе этой архитектуры.
Количество параметров. Параметры — это числовые значения, на которых базируются «решения» модели. Их количество показывает масштаб модели и ее потенциальные возможности. Параметры можно сравнить с количеством слов, которые знает человек. Чем больше у модели нейросети параметров — тем она умнее и креативнее, и тем выше ее способность выдавать связные и уникальные ответы.
Для сравнения: GPT-3 содержит 175 млрд параметров, а GPT-4, по неофициальным данным, — более сотни триллионов. Однако у моделей с огромным количеством параметров выше требования к вычислительным ресурсам. Для их запуска нужна и более продвинутая техника, и энергии они «съедают» больше. Поэтому разработчики создают маленькие модели с небольшим количеством параметров для мобильных устройств и приложений. Например, GPT-4o-mini или Claude Haiku.
Обучающие данные. Ответы модели нейросети напрямую зависят от информации, на которой ее обучали. Чаще всего в них загружают книги, тексты из открытого доступа, диалоги, код, изображения. Почти как человек, ИИ обрабатывает полученные данные и на их основе генерирует ответы на промпты. Если информация устарела, то модель модель может выдать неактуальные события и факты.
До появления режима Web Search во многих ИИ-сервисах вроде ChatGPT, QwenChat, LeChat модели не могли рассказывать о свежих новостях или находить новейшие источники в интернете.
Целевая задача. Каждая модель разрабатывается под конкретную цель: классификация, генерация, анализ, распознавание, поиск. От задачи зависит выбор архитектуры и критерии оценки ее качества. Например, модели для генерации текста (GPT, LLaMA) строятся по трансформерной архитектуре и обучаются на текстах.
Метод обучения. Существует несколько подходов к обучению моделей. От выбранного метода зависит не только то, что модель умеет, но и как она себя ведет.
Инженер по машинному обучению (NLP) в центре анализа данных ВАВТ
Если три основных метода обучения:
В современных языковых моделях, как правило, комбинируются все три подхода — от базовой предобученности до тонкой настройки с участием пользователей.
Производительность. Чтобы понять, насколько хорошо модель справляется со своей задачей, ее тестируют на стандартных наборах заданий под названием бенчмарки.
Бенчмарк — это своего рода экзамен для нейросети. Он включает типовые вопросы, задачи или данные, на которых можно объективно сравнить разные модели. Это могут быть тесты на понимание текста, задания на логическое мышление, перевод предложений, классификация изображений и многое другое.
Бенчмарки моделей и их версий обычно публикуются на сайтах компаний-разработчиков. Например, результаты тестирования GPT можно найти на сайте OpenAI, а информацию о возможностях Claude 3.7 Sonnet — на странице Anthropic. Сравнения моделей и рейтинги от пользователей публикуют на платформах Chatbot Arena и LLMArena.
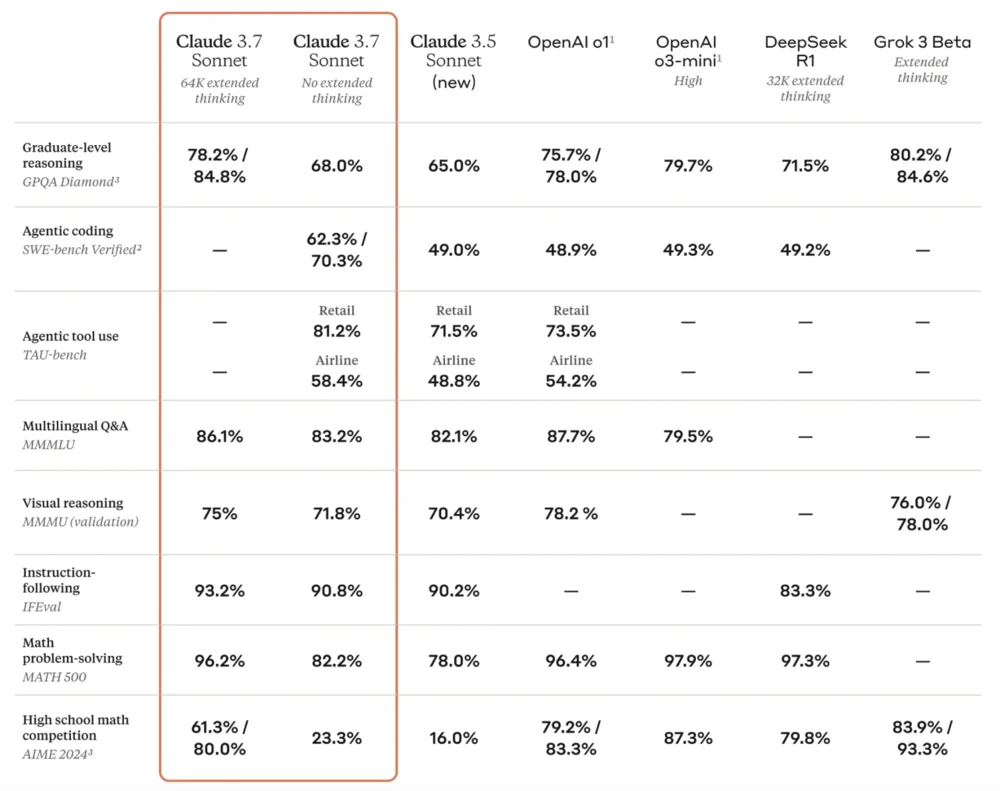
Когда речь заходит об ИИ, то на ум сразу приходит ChatGPT — нейросетевой сервис, который работает на основе сразу нескольких моделей и их версий.
Модели семейства GPT, известные под названиями GPT-4, GPT-4o и так далее. Они предназначены для генерации текста, его анализа, решения математических задач и создания кода. Кроме того, модели нейросети обладают компьютерным зрением, начиная с версии GPT-4, поэтому умеют изучать загруженные документы и картинки.
На апрель 2025 года самой сильной и умной считается модель GPT-o3 из подсемейства omni. Фишка этого подсемейства — умение думать, рассуждать и решать более сложные и комплексные задачи по сравнению с другими моделями.

Whisper — модель для распознавания речи. Вступает в дело, если человек использует голосовое управление. Whisper тоже «трансформер» по архитектуре, но заточенный под звуковые данные: он распознает и транскрибирует речь, хорошо справляется с шумом, акцентами и разными языками.
Codex — модель, которая разбирается в программировании. Она использовалась в более ранних версиях ChatGPT. Сейчас за написание кода отвечают модели GPT версии 4 и выше.
Если рассмотреть QwenChat от Alibaba, то и здесь «под капотом» окажется несколько моделей.
Qwen — основная универсальная модель, которая подходит для широкого круга задач: ответы на вопросы, генерация текста, перевод, решение математических задач.
Qwen-Audio — предназначена для работы с аудиоданными.
Qwen-Coder — специализированная модель для генерации программного кода. Она поддерживает множество языков программирования: Python, Java, C++, JavaScript и другие.
Qwen-Math — модель, специально обученная для решения математических задач.
Некоторые модели нейросетей нельзя выбрать вручную в интерфейсе — они просто «вшиты» в саму архитектуру сервиса и работают на фоне. Например, в списке доступных моделей ChatGPT вы не увидите Whisper, а у QwenChat — Qwen-Audio. Напрямую с ними не поработаешь — только через API и интеграции.
Есть и сервисы, которые используют одну основную модель, как, например, Claude AI. Он работает на мультимодели Claude 3, которая отвечает сразу за текст и код, обладает компьютерным зрением. Но при этом инструмент не умеет генерировать картинки или поддерживать голосовое общение.
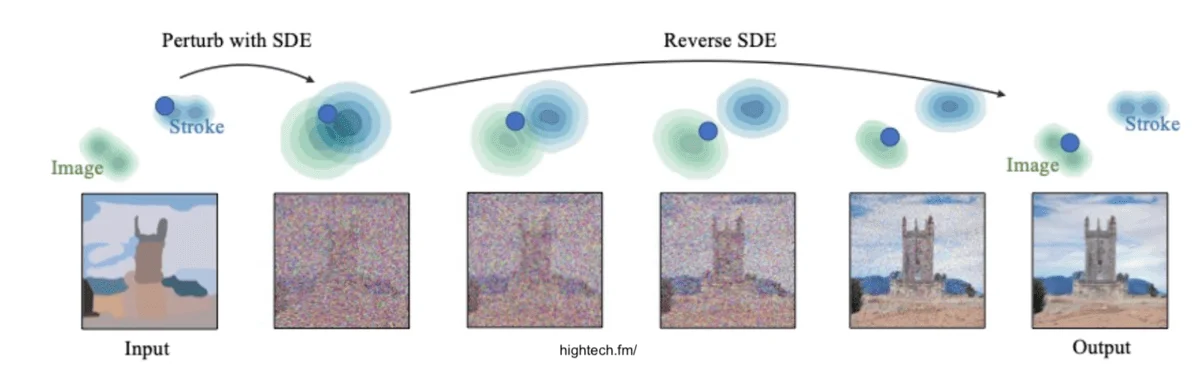
Такая же логика у генераторов изображений вроде Midjourney или Stable Diffusion. Каждый из них построен на одной одноименной модели, которая просто обновляется с каждой новой версией. Сами модели генерируют изображение из случайного набора пикселей, постепенно уточняя картинку шаг за шагом. В процессе обучения они учатся превращать «случайный шум» обратно в осмысленное изображение.
Модель нейросети — это обученная система, готовая решать конкретную задачу: генерировать текст, переводить, распознавать изображения и т. д.
Нейросеть — это архитектура, способ построения модели. Модель становится рабочим инструментом только после обучения.
Версия модели — это новая итерация: улучшенное качество, новые возможности, оптимизация. Например, GPT-o3 — более умная и способная версия по сравнению с GPT-4o. Рассчитана на решение более сложных задач.
Модели отличаются друг от друга архитектурой, числом параметров, обучающими данными, целевыми задачами и ресурсоемкостью. Эти характеристики определяют, где и как можно использовать модель.
Большинство ИИ-сервисов работают не на одной, а сразу на нескольких моделях — каждая отвечает за свой: текст, код, изображение, голос или анализ данных.
Читайте только в Конверте




Всё для быстрого старта в email: блочный редактор, 200 шаблонов, ИИ-помощник.
Промокод FB26K даёт скидку 99% на первый месяц тарифа «Лайт» или «Стандарт». До 28 февраля включительно.

Искренние письма о работе и жизни, эксклюзивные кейсы и интервью с экспертами диджитала.
Проверяйте почту — письмо придет в течение 5 минут (обычно мгновенно)



