 Говори как маркетолог
Говори как маркетолог Оплачивайте подписки, маркетплейсы и зарубежные площадки с виртуальной банковской картой.
Exnode поможет выбрать, где оформить карту онлайн без скрытых комиссий.
Как алгоритмы учатся решать задачи бизнеса

Обучение модели — это процесс тренировки программы находить закономерности, классифицировать объекты и делать прогнозы. Благодаря этому модели могут выполнять сложные операции. Например, генерировать текст и изображения, прогнозировать спрос на товары, подбирать рекламные предложения под интересы пользователя. И это далеко не полный список возможностей.
Разбираем в статье, как происходит обучение моделей и где оно применяется.
Способность программ анализировать данные и делать прогнозы появилась благодаря машинному обучению (Machine Learning, ML). Это технология, которая позволяет компьютеру учиться на примерах и самостоятельно выявлять взаимосвязи, а не действовать по заранее написанным жестким правилам.
Например, чтобы обучить модель прогнозировать спрос на товар, не нужно заранее прописывать алгоритм действий. Достаточно загрузить данные в систему и описать нужный результат. Модель проанализирует историю продаж, сравнит свои прогнозы с реальными результатами и самостоятельно найдет скрытые закономерности. К примеру, определит, что сезонные акции увеличивают продажи на 30%, а рост цен у конкурентов — на 5%. После обучения модель сможет сделать точный прогноз на будущий период с учетом новых данных о ценах и акциях.
Когда нужно проанализировать большие массивы данных, в которых сложно выявить закономерности, используют определенный тип машинного обучения — нейронные сети. В отличие от традиционных компьютерных алгоритмов, они хорошо справляются со сложными задачами: например, распознают объекты на изображении, обрабатывают тексты, генерируют контент.
Обучение моделей нейросетей состоит из этапов:
Сбор и подготовка данных. Данные собирают из разных источников, очищают от ошибок и дубликатов, приводят к единому формату. Чем больше качественных данных, тем точнее работает модель. Например, для обучения системы распознавания лиц нужны тысячи фотографий людей под разными углами и с разным освещением. Если в данных для распознавания лиц будут только дневные фото, модель может не узнать человека на вечернем снимке.
Выбор архитектуры. В зависимости от задачи подбирают определенный тип нейросети. Например, для распознавания изображений подходят сверточные нейронные сети (CNN), для генерации текста — трансформеры (Transformer). Для анализа числовых показателей и прогнозирования используют рекуррентные нейросети или классические методы машинного обучения.
Подбор метода обучения. Это определяет, как модель будет взаимодействовать с данными. Основные методы:
Методы могут использоваться как по отдельности, так и в комбинации. Например, в моделях GPT сочетаются обучение с учителем и обучение с подкреплением. Благодаря этому нейросеть сначала учится на примерах, а затем улучшает ответы на основе обратной связи.
Процесс обучения. Модель состоит из слоев нейронов и связей между ними. У каждой связи есть числовой параметр — вес. Чем он больше, тем сильнее влияние нейрона на прогноз. Во время обучения система изучает подготовленные данные и итерационно настраивает веса, чтобы уменьшить разницу между прогнозом и правильным ответом. Цикл повторяется множество раз, пока точность не достигнет нужного уровня.
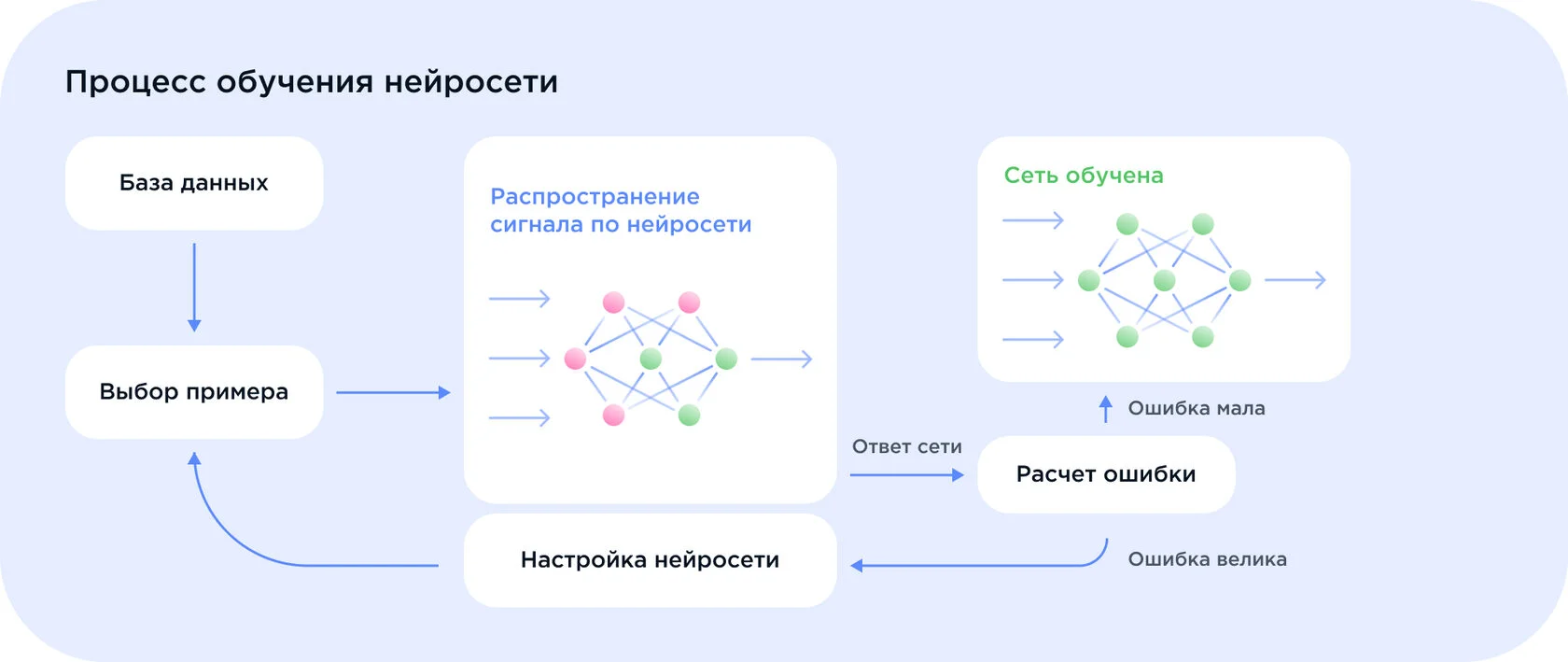
Оценка качества. После обучения модель тестируют на данных, которые она раньше не видела. Это позволяет оценить, насколько хорошо она применяет полученные знания к новым ситуациям и дает точные прогнозы.
Развертывание. Готовую модель встраивают в рабочую систему, например, в сайт, мобильное приложение или CRM. После этого модель начинает работать с реальными пользователями и данными, решая практические задачи.
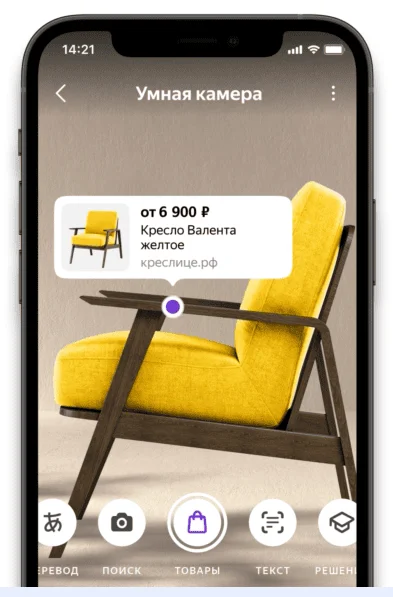
Распознавание объектов. Системы идентификации лиц анализируют людей по внешним параметрам: форме носа и губ, цвету глаз, овалу лица. Такие технологии применяют в аэропортах для ускорения паспортного контроля, в офисных зданиях для доступа сотрудников, в поисковых системах. Например, умная камера в приложении Яндекс распознает объект на фото, выдает краткую информацию о нем или ссылку на похожий товар в маркетплейсе.
Прогнозирование и аналитика. С помощью обученных моделей рекламные платформы прогнозируют вероятность клика по объявлению и показывают рекламу тем, кто скорее всего совершит целевое действие. В бизнесе такие модели помогают оценивать потенциальный спрос на товары и услуги. Например, в ритейле это позволяет оптимизировать складские запасы и не терять выручку из-за нехватки нужных товаров.
Так в сети «Перекрёсток» X5 Retail Group внедрили систему прогнозирования спроса на основе машинного обучения, которая учитывает около 200 факторов: цены, ассортимент, продажи, товарные остатки, рекламные активности, конкурентная среда. Система анализирует данные по 846 магазинам и прогнозирует спрос на товары с точностью более 70%. В результате торговая сеть получила рост валового дохода, повысила эффективность выполнения плана магазина, сократила товарные запасы и списания.
Скоринг и оценка рисков. Банки используют скоринговые модели для оценки кредитоспособности заемщиков. Система анализирует текущие и прошлые долги, наличие имущества, место работы, уровень дохода и выдает скоринговый балл — вероятность, что клиент вовремя вернет кредит. Это помогает ускорить проверку и снизить количество невозвратов.
Рекомендательные системы. Обученные модели анализируют поведение пользователей и предлагают персонализированные рекомендации. Например, в Яндекс Музыке и Spotify подбирают треки на основе истории прослушиваний пользователя и предпочтений людей с похожими вкусами. А маркетплейсы рекомендуют товары, которые с высокой вероятностью заинтересуют конкретного покупателя.
Обработка текста и генерация контента. Современные языковые модели вроде ChatGPT, Claude, Gemini помогают автоматизировать рутинные задачи. Их интегрируют в чат-боты для быстрой поддержки клиентов, используют для массовой генерации описаний товаров и рекламных текстов, а также для анализа тысяч клиентских отзывов. В бизнесе такие модели позволяют ускорить обработку данных и производство контента.
Выявление мошенничества. С помощью обученных моделей банки отслеживают подозрительные транзакции в режиме реального времени. Система анализирует операцию: сумму, время, геолокацию, устройство — и блокирует карту, если обнаруживает аномалии. Например, если карта используется в другой стране или совершается очень крупная покупка.
Большие объемы данных и ресурсов. Для обучения качественной модели нужны тысячи или миллионы примеров. Разработка обходится дорого, поэтому чаще всего этим занимаются крупные IT-компании. Но бизнес также может использовать готовые обученные модели и адаптировать их под свои задачи — это быстрее и дешевле.
Подготовка данных. Недостаточно просто собрать информацию. Ее нужно очистить от дубликатов и ошибок, привести к единому формату и разметить так, чтобы модель правильно определила объекты и его признаки. Например, чтобы обучить систему распознавать эмоции на лицах, на каждой фотографии указывают, какая эмоция выражена: радость, грусть или удивление.
Регулярное переобучение. Модель, обученная на старых данных, постепенно теряет актуальность. Меняются потребительские предпочтения, появляются новые товары и тренды. Рекомендательная система, которая отлично работала год назад, сегодня может выдавать нерелевантные результаты. Поэтому модели нужно периодически обновлять: добавлять свежие данные и переобучать.
Риск недообучения. При недостаточном объеме данных модель ищет простые закономерности и работает поверхностно. Она может справляться с тестовыми примерами, но ошибаться на реальных данных. Например, если модель для определения спама обучили только на рекламных письмах интернет-магазинов, она пропустит фишинговое письмо от имени банка, потому что не видела таких примеров.
Обучение модели позволяет программам находить закономерности и делать прогнозы без заранее прописанных правил. Системы помогают бизнесу прогнозировать спрос, персонализировать рекомендации, оценивать риски, генерировать контент и распознавать объекты на изображениях.
Модели применяются в ритейле, банковских услугах, маркетинге, аналитике. Их обучают на больших данных, тестируют на новых примерах и внедряют в рабочие системы. Это позволяет автоматизировать рутину и принимать более точные решения.
Оплачивайте подписки, маркетплейсы и зарубежные площадки с виртуальной банковской картой.
Exnode поможет выбрать, где оформить карту онлайн без скрытых комиссий.

Искренние письма о работе и жизни, эксклюзивные кейсы и интервью с экспертами диджитала.
Проверяйте почту — письмо придет в течение 5 минут (обычно мгновенно)


