UTF-8 (Unicode Transformation Format, 8-bit) — это кодировка, или система кодирования символов. Она работает по стандарту Unicode, где каждому символу присвоен номер.
Новое медиа о том, как обычным людям использовать нейросети в работе и жизни.
Все, кому интересен ИИ, заходите!
Это медиа для вас.
Компьютеры работают не с буквами и символами, а с числами в двоичной системе счисления. Каждое число кодируется как комбинация нулей и единиц. Чтобы перевести информацию в понятный человеку вид, существуют кодировки. Их можно представить как таблицы, где каждый символ, буква или знак препинания обозначается каким-то двоичным числом.
Название символа в кодировке UTF-8 обозначается как «U+(число)». Числа для удобства обычно переводят в шестнадцатеричную систему счисления. Например, U+0411 — это заглавная буква Б.

Так выглядит часть таблицы кодировки UTF-8. Фактически это словарь для перевода с машинного языка на человеческий. Источник
Как устроена кодировка UTF-8
UTF-8 — одна из самых популярных кодировок. Ее название означает Unicode Transformation Format — формат кодировки Юникода.
Unicode, или Юникод — стандарт кодирования, принятый в 1991 году. Он позволяет закодировать более миллиона символов: от латинских букв до иероглифов и нотных знаков. Сейчас Юникод считается одним из самых распространенных стандартов, хотя он не единственный.
Число 8 в названии кодировки говорит, что она восьмибитная. Бит — это минимальная единица измерения информации, она может содержать только число 0 или 1. Восемь бит называются байтом. Именно в байтах измеряется количество информации, которым кодируют символы в UTF-8. Один символ может занимать от 1 до 4 байтов: в этой кодировке на один знак выделяют переменное количество памяти.
Какие символы весят много, а какие мало — зависит от их популярности. Если символ используют часто и во многих языках, его место в таблице будет выше, а памяти он будет отнимать меньше. И наоборот: редкие символы занимают по 3–4 байта.
| Количество байтов | Какие символы входят |
| 1 | Простые знаки препинания и пробел, латинские буквы и арабские цифры |
| 2 | Кириллица, иврит, греческий, арабский и другие более редкие алфавиты, некоторые знаки препинания |
| 3 | Сложная письменность вроде китайских или японских иероглифов, индийского или грузинского письма, сложные знаки препинания и математические символы |
| 4 | Символы редких и вымерших языков, музыкальные символы, сложные иероглифы |
Кроме UTF-8, существуют кодировки UTF-16 и UTF-32. В UTF-16 один символ занимает 16 бит, а в UTF-32 — 32 бита. Информация в таких кодировках обычно отнимает больше памяти. Даже популярные символы будут занимать 16 или 32 бита — а в UTF-8 они будут весить всего 8 бит. Поэтому такие кодировки используют реже, чтобы тексты занимали меньше места в памяти.
Особенности кодировки UTF-8
Совместимость с ASCII. Более простая кодировка ASCII — одна из старейших. В ней всего 128 символов. Это цифры, буквы латинского алфавита, знаки препинания и управляющие символы (в прошлом их использовали, чтобы отдавать команды устройствам). Первая четверть кодировки UTF-8 аналогична таблице ASCII, поэтому тексты на английском языке и числа можно легко переводить из одной кодировки в другую.
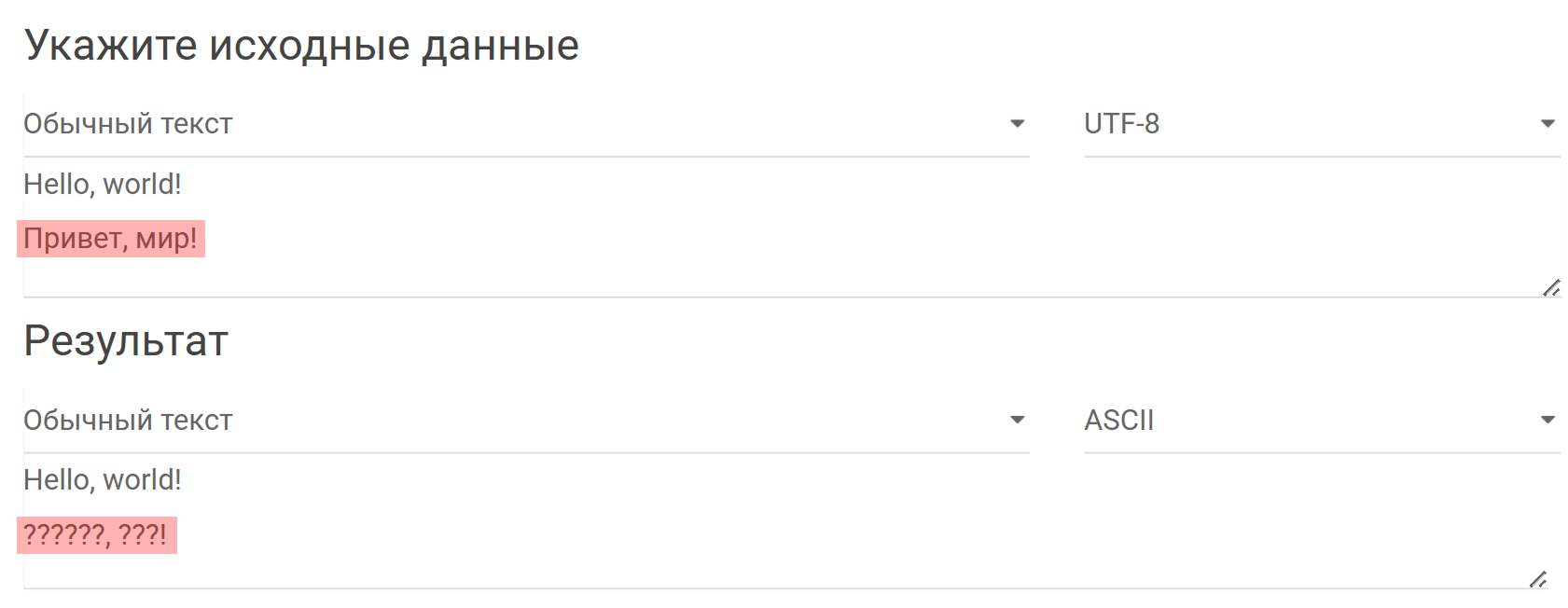
Если текст в кодировке UTF-8 состоит только из ASCII-символов, его можно преобразовать в более простую кодировку. Это позволит работать с текстом даже в программах, которые не поддерживают Юникод. А вот кириллицу так перевести не получится: в ASCII нет таких символов, и вместо букв отображаются вопросительные знаки. Источник
Все языки мира. В таблице Юникода помещается до 1 112 064 символов. Этого хватило, чтобы полностью закодировать все языки в мире, в том числе иероглифические и древние — вроде старославянского. И в таблице до сих пор осталось 80% свободного места.

Например, в азиатских языках несколько тысяч иероглифов, которые к тому же могут записываться по-разному. И все они есть в Юникоде. Источник
Переменное количество памяти. В отличие от многих других кодировок, в UTF-8 на один символ может уходить разное количество памяти. Цифры и английские буквы занимают по 1 байт информации на символ. Буквы на русском языке — уже 2 байта. А древнегерманская буква 𐍈 (хвайр) кодируется 4 байтами. Но и используют ее очень редко.
Разные способы кодирования. Существуют составные символы — они включают несколько элементов. UTF-8 позволяет кодировать их и как отдельные символы, и как сумму элементов. Например, букву Й можно обозначить как единый символ с номером U+0419. А можно — как сочетание символа И (U+0418) и диакритического знака ̆ (U+0306).
Сложная система вычислений. Компьютер проводит вычисления, чтобы перевести двоичный код в текст. В UTF-8 перевод довольно сложный и многоэтапный — это связано с переменным количеством памяти и разными способами записи символов. Поэтому Юникод с осторожностью используют в системах, где важно тратить как можно меньше вычислительных ресурсов, например в одноплатных компьютерах.
Преимущества и недостатки UTF-8
UTF-8 стала самым распространенным стандартом кодирования благодаря нескольким преимуществам:
- содержит практически все символы, которые используются в текстах на разных языках;
- более компактная, то есть занимает меньше места, чем UTF-16 и UTF-32;
- совместима практически с любыми программами, системами и браузерами.
Главный недостаток UTF-8 связан со сложной системой кодирования. Из-за этого при его использовании могут возникать ошибки. Например, если большое количество символов передается между сервером и клиентской частью сайта, может переполниться стек — то есть нужно будет передать больше информации, чем возможно. Из-за этого может возникнуть сбой.
Кроме того, иногда символами Юникода могут пользоваться злоумышленники, чтобы подменять текст. Например, хакеры способны добавить в название файла символ, из-за которого буквы отображаются в другом порядке. Человек думает, что файл безопасен — а на самом деле там вредоносный код.
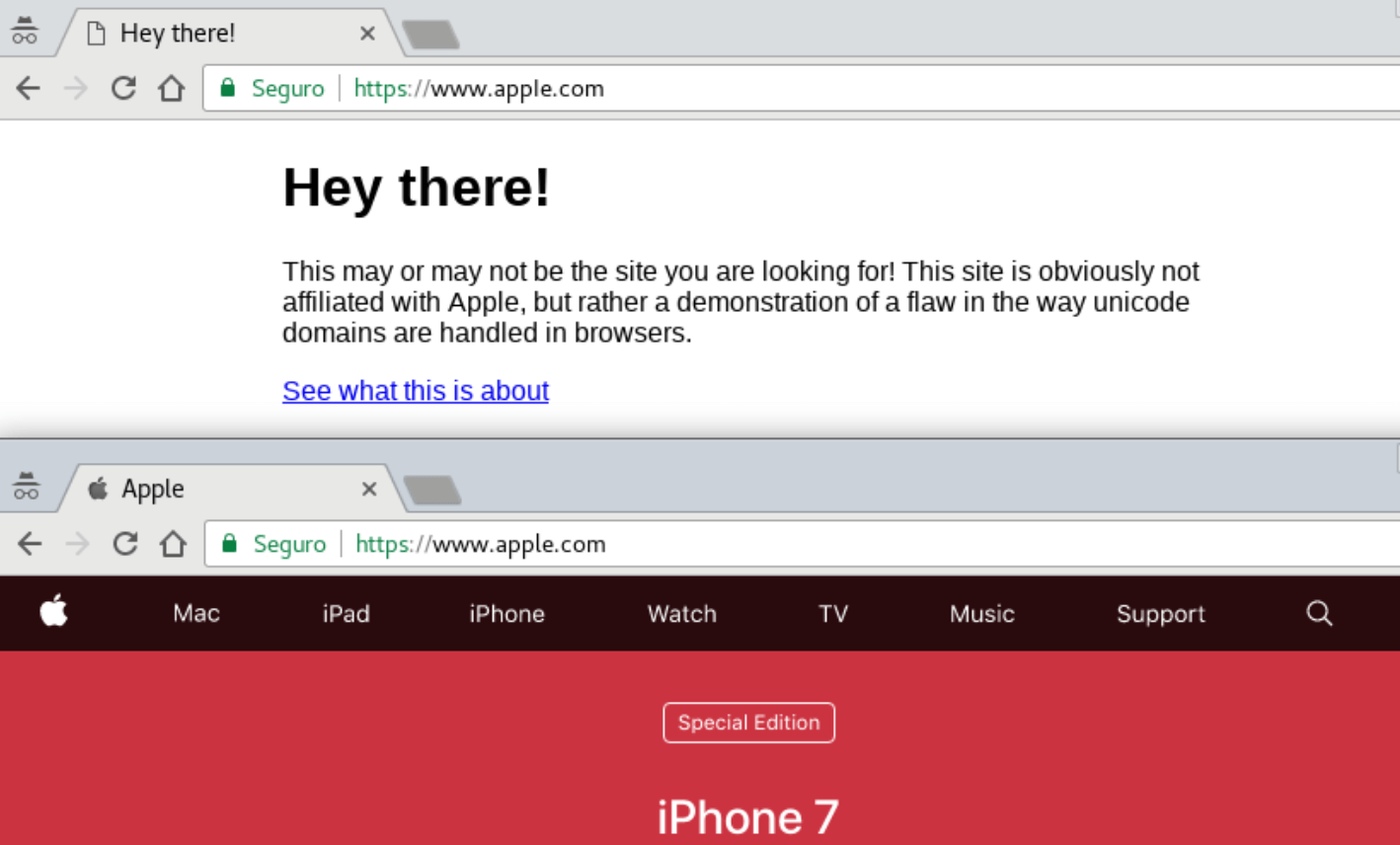
Еще один пример мошенничества с использованием UTF-8 — Unicode Domain Phishing, или фишинг доменов в Юникоде. Злоумышленники создают сайты, в имени которых латинские буквы заменены на похожие внешне кириллические. Адрес такого сайта выглядит как настоящий, но на самом деле ссылка ведет на поддельный ресурс. Источник
Недостатки UTF-8 в основном имеют значение для разработчиков. Обычные пользователи сталкиваются с ними довольно редко, а вот преимущества для них заметны сразу.
Как пользоваться кодировкой UTF-8
UTF-8 используют практически везде: на сайтах, в программах и файлах, в операционных системах. Некоторые из них автоматически выбирают UTF-8 как основную кодировку, поэтому у пользователей не возникает проблем с отображением символов.
А вот чтобы использовать UTF-8 на сайте, нужно явно указать, что на нём применяется именно эта кодировка. Поэтому в коде интернет-страниц обычно пишут строку:
<meta charset="UTF-8">
Она означает, что текст на странице нужно отображать в UTF-8. Если не добавить эту строчку, браузер может автоматически применить другую кодировку — и текст превратится в нечитаемый набор символов.

Так может выглядеть сайт, если кодировка страницы и сервера не совпадают. Текст невозможно прочесть, и пользователь уйдет с такого сайта
Чтобы такого не произошло, на странице и указывают кодировку. Также нужно убедиться, что информация, которую присылает на страницу сервер, тоже кодируется в UTF-8. Кодировку на стороне сервера можно посмотреть и изменить с помощью серверных скриптов.
Если тексты хранятся в базе данных, для них тоже нужно выставить кодировку UTF-8 — по той же причине. Это делается с помощью запроса на языке SQL. При создании таблицы нужно указать параметр CHARACTER SET utf8mb4. Он говорит, что информация в базе будет кодироваться UTF-8.
Главные мысли

- Юзабилити
- Авторитет домена (domain authority)
- XML
- Источники трафика
- Форма сбора лидов
- HTML
- Верстка сайта
- Дизайн сайта
- Диплинк
- Юникод



