
Поисковая система (поисковик) — это специальная программа, которая в ответ на запрос пользователя через веб-интерфейс (сайт) выдает список ресурсов, отсортированных по релевантности этому запросу.

Поручите ИИ работу над вашими письмами — от картинки до финального результата.
Это бесплатно.
Хорошая поисковая система предлагает материалы, которые наиболее корректно отвечают на запрос пользователя. При этом многие поисковики могут искать нужное не только по словам, но и по картинке или голосовому сообщению.
Прародителем поисковых систем считают программу Archie — первый инструмент для поиска контента в интернете. Archie предлагал пользователям архив со списком доступных файлов и возможностью поиска по ним.
В 1994 году появилась первая полноценная поисковая система — WebCrawler, которая стала индексировать не только названия файлов или заголовки страниц, но и их содержимое. А уже через три года, в 1997 году, на рынок вышли привычные нам Google и «Яндекс».
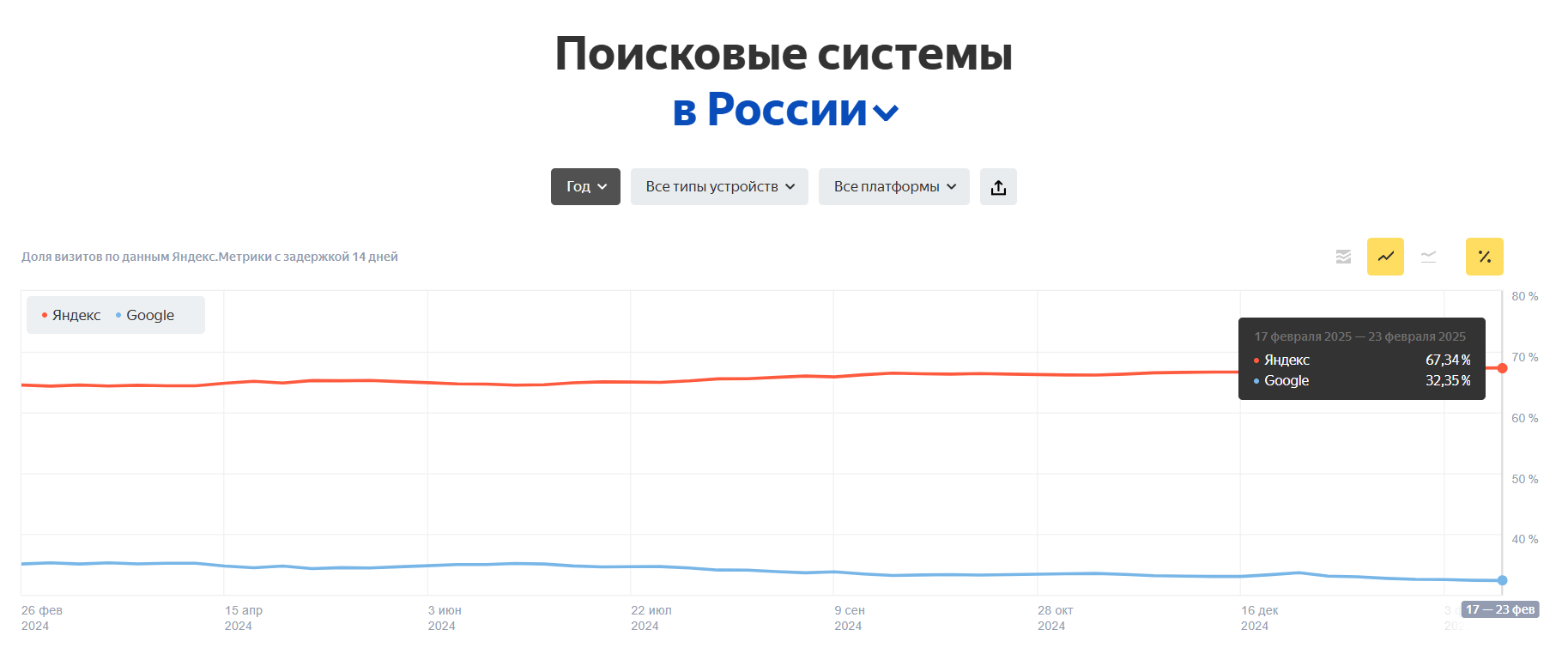
По данным «Яндекс Радар» Google и «Яндекс» все еще остаются самыми популярными поисковыми системами в России
Если обратиться к мировой статистике, то здесь лидирует Google (79,92%), а «Яндекс» (2,72%) уходит на 6-е место.
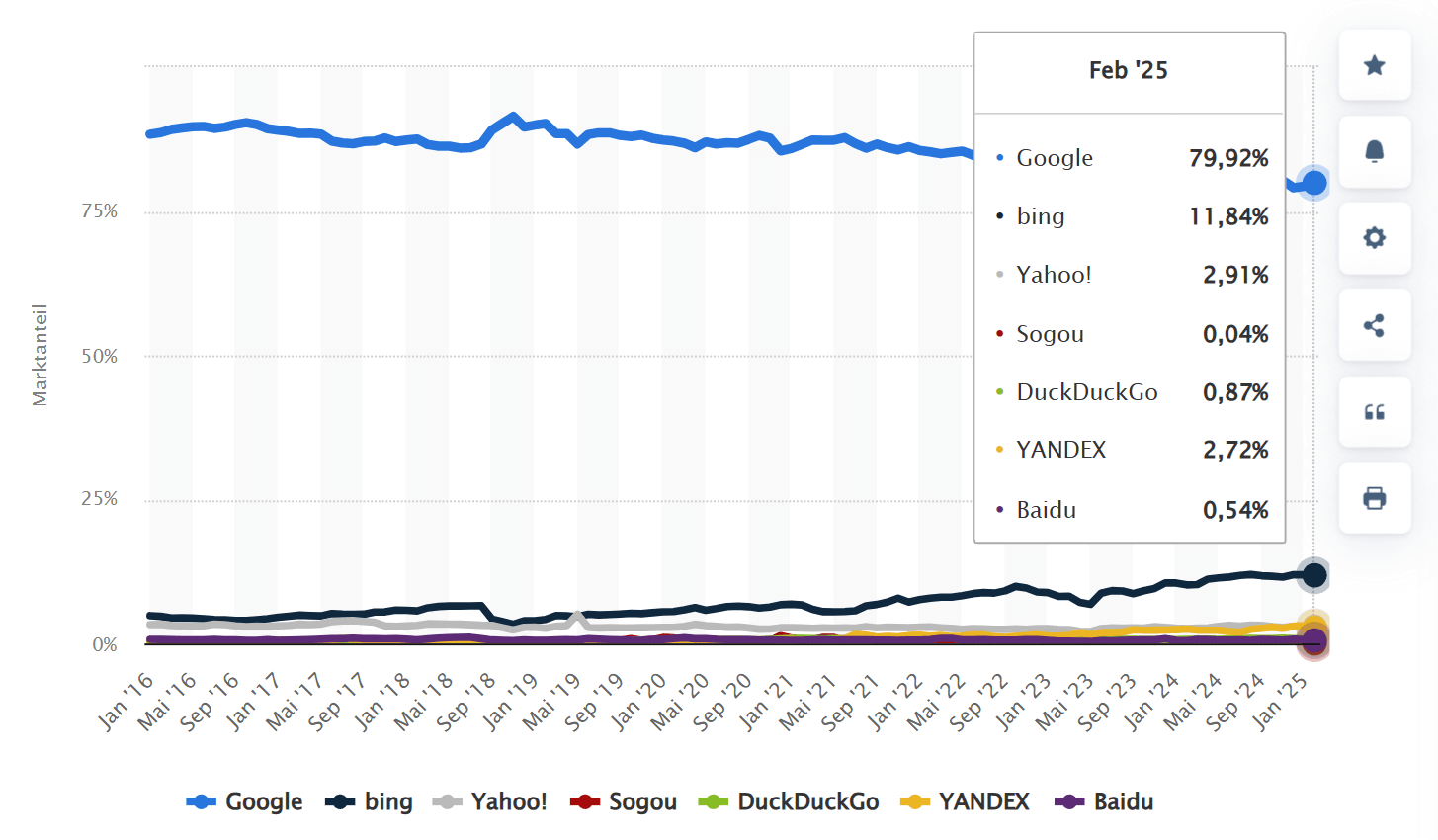
Доля рынка наиболее часто используемых поисковых систем по всему миру по состоянию на февраль 2025 г. Источник
Зачем нужна поисковая система
Без поисковых систем обычный пользователь вряд ли найдет в интернете нужную информацию, так как без них не будет привычного нам списка сайтов. Придется вручную вбивать адрес каждого ресурса, чтобы проверить, есть ли там то, что он ищет.
Алгоритмы поисковиков уже знают, какая информация есть на большинстве сайтов, и в ответ на запрос выдают список страниц, которые больше всего соответствуют этому запросу.
Кроме того, современные поисковые системы давно вышли за границы обычных поисковиков и превратились в целые экосистемы, которые помогают пользователям решать множество бытовых и бизнес-задач. В «Яндексе» есть электронная почта, маркетплейс, онлайн-кинотеатр, такси, доставка еды, карты, различные сервисы для бизнеса, а еще собственная платежная система и голосовой помощник Алиса.
У «Яндекса» так много сервисов, что они не помещаются на одном экране
Большинство поисковых систем не так популярны, как «Яндекс» и Google, но все же могут быть полезны в конкретных нишах или предлагать больше конфиденциальности.
Не только Яндекс и Google: 7 альтернативных поисковых систем
Например, поисковая система DuckDuckGo не собирает и не хранит данные о посетителях, а значит, обеспечивает максимальную конфиденциальность своим пользователям. Поисковик также не учитывает предпочтения, поэтому выдача получается более объективной.
Пример с более узким направлением — поисковик по звукам FindSounds. В поисковую строку можно ввести текстовый запрос или загрузить образец и получить на выходе аудиофайл.
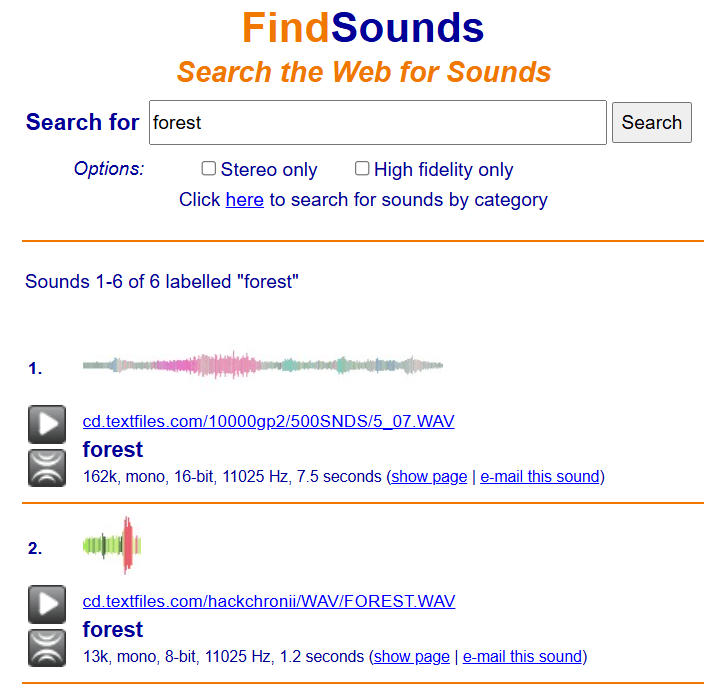
По запросу «forest» FindSounds списком выдает аудиофайлы и информацию о них
Этапы работы поисковиков
У каждой поисковой системы — свой алгоритм работы, который держится в строгом секрете. Однако условно весь процесс подбора нужной информации поисковиком можно разделить на три этапа: сканирование, индексация и ранжирование.
Сканирование
Чтобы поисковая система смогла найти нужную информацию в большом количестве сайтов, эти сайты должны быть ей известны, то есть прочитаны и сохранены в памяти.
Можно сравнить с библиотекой: если вы не знаете, какие книги стоят на полках и никогда не заглядывали в них, то вероятность того, что вы быстро сориентируетесь и найдете нужную цитату, равна нулю.
Поисковая система узнает о содержимом сайтов с помощью специального робота — краулера, или паука. Название происходит от английского crawler (ползающее насекомое, ползунок). Робот обходит все страницы, переходит по ссылкам и постепенно охватывает миллиарды веб-страниц в сети, сохраняет их и отправляет на индексацию.
Индексация
Следующий этап — подробный анализ загруженных страниц и добавление информации о том, какие сведения в них содержатся, в базу поисковой системы (создание индекса).
Индексный робот разбивает каждую сохраненную страницу на части (заголовки, текст, ссылки, теги html и т. д.), изучает их содержимое, анализирует и структурирует. В результате получается упорядоченный список адресов страниц и размещенной на них информации.
По аналогии с библиотекой: недостаточно знать, какие книги есть на полках. Важно составить подробный и удобный каталог, который расскажет, в каких книгах и на каких страницах искать нужную информацию.
Другой пример — предметный указатель в справочниках, который помогает без труда найти ответ на нужный вопрос. Все термины здесь размещены по алфавиту с указанием страниц, на которых они встречаются. Источник

Пока страница не проиндексирована, для поисковика она не существует. Поэтому важно, чтобы сайт был открыт для индексации. При необходимости можно закрыть от поисковых роботов отдельные страницы, например личный кабинет и корзину, чтобы они не попали в выдачу.
Если страница открыта для индексации, то самая распространенная причина того, что она не появляется в выдаче — она новая, и поисковый робот просто не успел ее проиндексировать.
В зависимости от характеристик сайта и возможностей поисковых роботов обновление или апдейт страниц может занять от нескольких минут до нескольких недель.
Проверить индексирование страницы можно в «Яндексе Вебмастере» в разделе «Индексирование», а в Google Search Console — «Проверка URL».
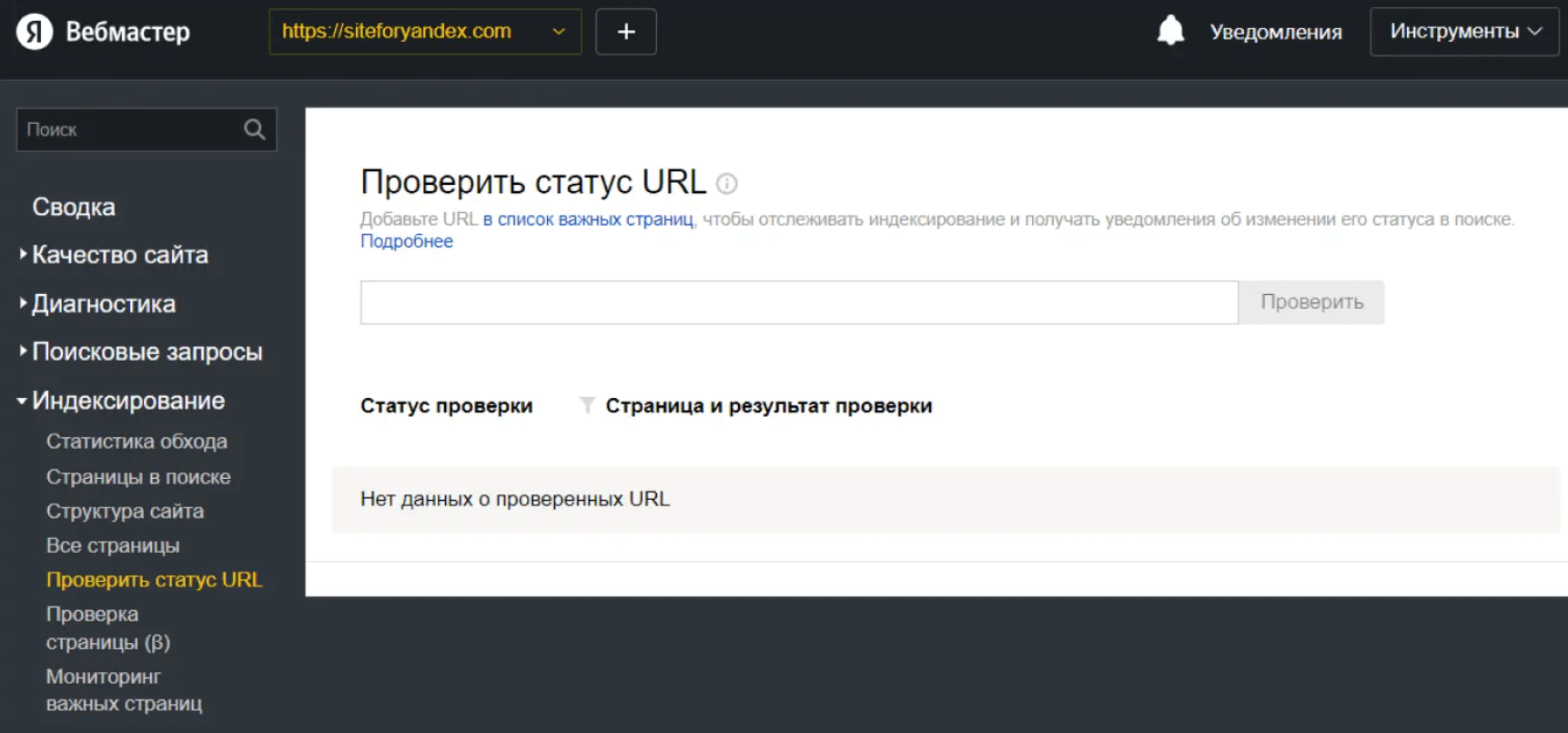
«Яндекс Вебмастер» помогает понять, виден ли сайт в поисковой выдаче. Источник
Также в «Яндекс Вебмастере» можно направить страницы сайта на индексацию вручную с помощью функции «Переобход страниц», а в Google Search Console — сделать запрос индексирования.
Ранжирование и поисковая выдача
Когда человек вводит запрос в поисковую строку, поисковик выбирает все страницы, которые имеют отношение к запросу, прогоняет их через свои алгоритмы и выдает список сайтов в определенном порядке. При этом чем выше сайт оказался в выдаче, тем лучше он соответствует запросу пользователя и требованиям поисковика.
Процесс сортировки сайтов по определенному списку критериев называется ранжированием. На его результаты влияет релевантность контента запросу, качество и удобство сайта, его технические и пользовательские характеристики и многое другое. Точный список критериев поисковые системы держат в секрете и постоянно обновляют свои алгоритмы.
По итогам ранжирования можно получить разные результаты, если искать:
- в разных поисковиках, так как используются различные критерии фильтрации;
- в разных регионах, так как в запросах учитывается местонахождение пользователя;
- на разных устройствах — в десктопной и мобильной версии, так как имеет значение удобство использования сайта на разных устройствах;
- у разных пользователей по одинаковым запросам так как учитывается индивидуальная история поиска.
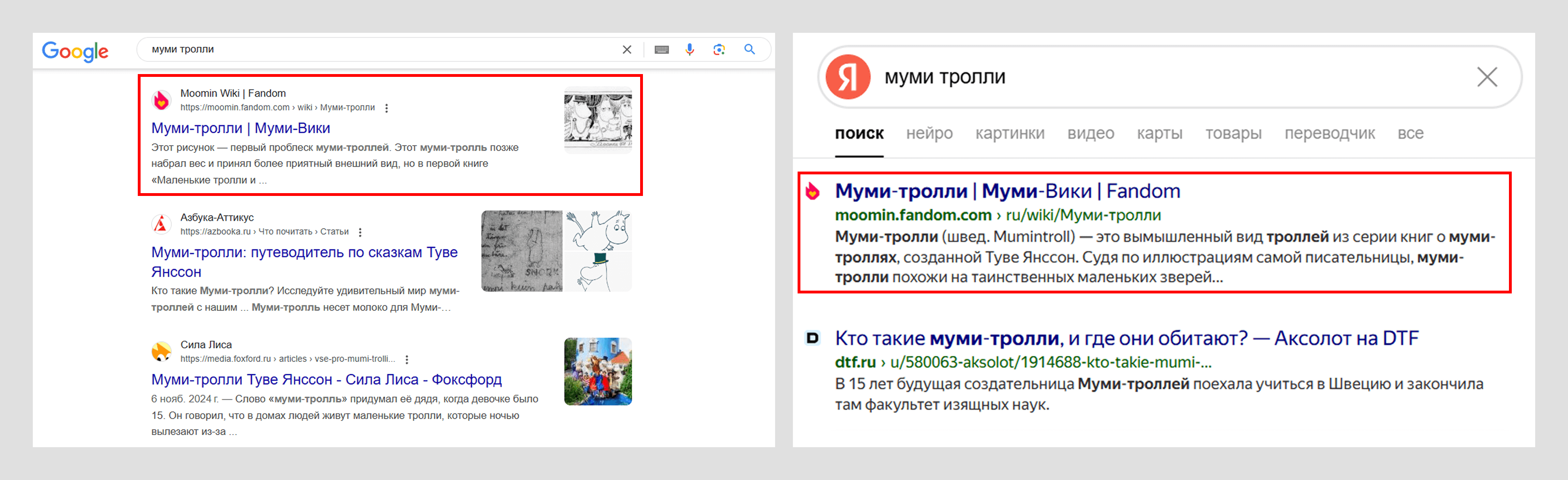
По запросу «муми тролли» Google и «Яндекс» выдают разные результаты. На первых страницах совпадает только три сайта из десяти
Ранжирование позволяет пользователям быстрее получить нужную и достоверную информацию, а компаниям использовать поисковую выдачу для продвижения своего сайта.
Главные мысли




