Large Language Model — это модель искусственного интеллекта, которая понимает и генерирует текст на человеческом языке.
Новое медиа о том, как обычным людям использовать нейросети в работе и жизни.
Все, кому интересен ИИ, заходите!
Это медиа для вас.
Large Language Model дословно переводится как «большая языковая модель». В русском языке иногда используют аббревиатуру «БЯМ».
Это разновидность искусственного интеллекта, то есть система, которая имитирует мышление человека. Конкретно LLM умеет распознавать и создавать тексты.
Самые известные LLM: Chat GPT, DeepSeek, Gemini, LLaMA, Claude, GigaChat, YandexGPT.
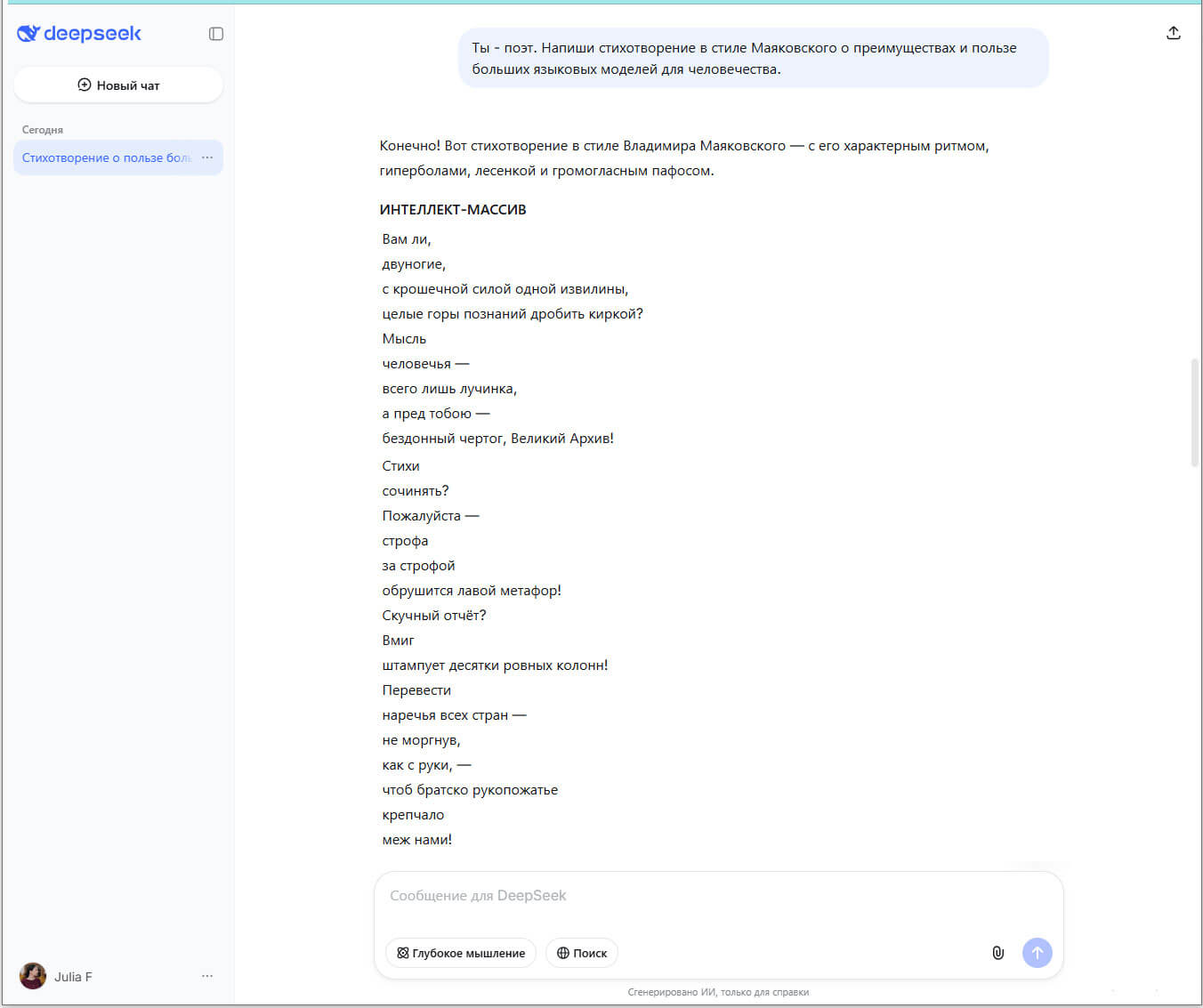
Интерфейс большой языковой модели DeepSeek
Слово «большой» в названии используется по двум причинам:
- модель обучается на большом объеме информации, включая книги, статьи, сайты, исследования, публикации в социальных сетях;
- модель включает большое количество параметров, которые содержат информацию о том, как слова связаны друг с другом.
Большие языковые модели требуют больших вычислительных мощностей. Процесс обучения LLM длится от нескольких недель до нескольких месяцев, для этого требуется тысячи процессоров и много электроэнергии.
Где используют Large Language Model
Генерация контента. Большие языковые модели умеют создавать тексты в разных жанрах и любой сложности. Посты для социальной сети, сценарии рекламных роликов, тексты для лендинга, лонгриды. При этом модель будет придерживаться заданного стиля, Tone of Voice, структурирует текст, оптимизирует его для SEO.
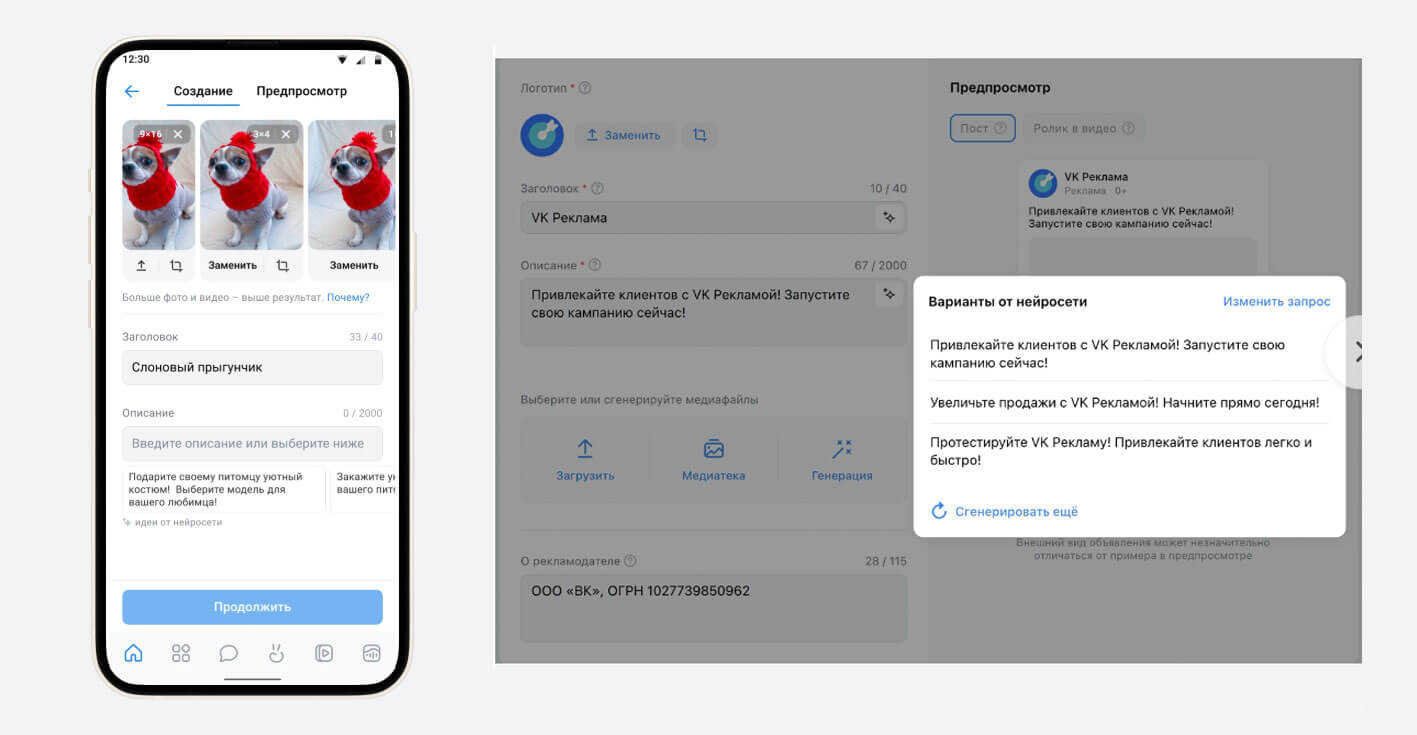
В VK Рекламе пользователи могут генерировать текст для объявлений с помощью встроенного ИИ-инструмента
Создание кода. LLM умеет работать не только с человеческими языками, но и с языками программирования. Модели способны генерировать, оптимизировать и дополнять код, находить ошибки. ИИ берет на себя рутину, а разработчик может сосредоточиться на творческих и стратегических задачах.
Это направление получило название «вайбкодинг», от английского «vibe coding». Разработчик ставит задачу на естественном языке, а искусственный интеллект генерирует код.
Программист простыми словами пишет задачу для LLM. Модель генерирует код и дает обратную связь по его работе
Чат-боты. LLM хорошо понимают задачи на естественном языке и анализируют контекст. Поэтому их используются для чат-ботов или виртуальных ассистентов, которые помогают пользователям решать проблемы.
Чат-боты на базе LLM не просто отвечают заученными фразами по алгоритму, как это было в прошлом десятилетии. Они понимают суть запроса и дают релевантные ответы. Их используют как консультантов, чтобы рассказать о товарах и услугах, в техподдержке и клиентском сервисе — для обработки жалоб и решения проблем клиентов, оформления заказов.
Суммаризация. Языковая модель способна быстро изучить большой объем текста и выделить ключевые идеи. Пользователю больше не нужно читать отчет или исследование на 100 страниц, достаточно отправить документ в чат-бот.
ИИ подготовит краткую справку с основными выводами и идеями. На основе саммари пользователь понимает, есть ли в тексте интересная и полезная для него информация и принимает решение, знакомиться с полной версией или нет.
«Яндекс Браузер» использует ИИ, чтобы кратко пересказать содержание страницы
Перевод. У большой языковой модели нет «родного» языка. Она «знает» практически многие языки, что делает ее универсальным переводчиком. Модель позволяет быстро перевести большие объемы текста, сохранить стилистику, контекст, юмор и сленг.
Анализ настроений. Большие языковые модели распознают эмоциональный тон текстов. С их помощью компания может быстро проанализировать большой объем отзывов и определить уровень удовлетворенности клиентов продуктом.
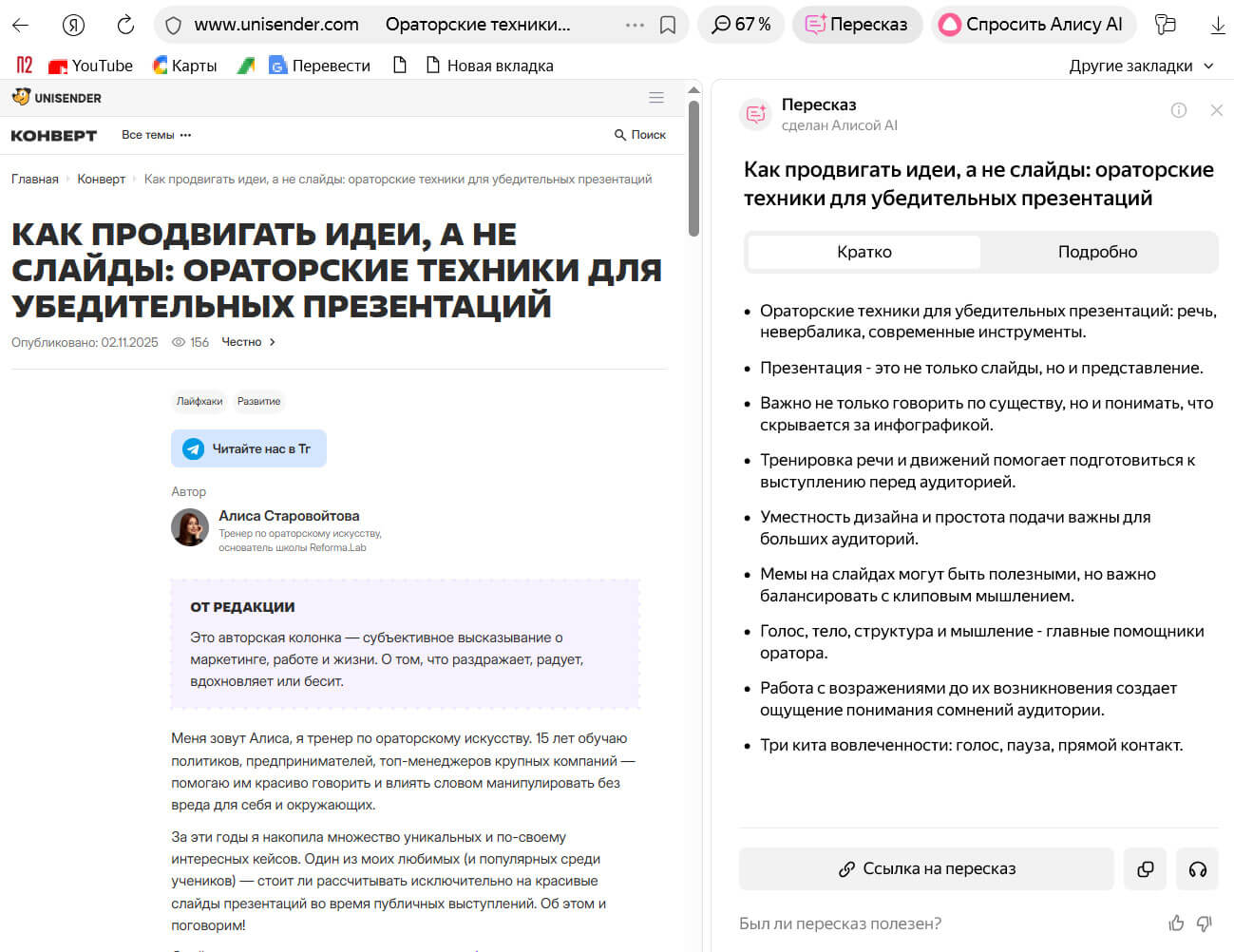
Компания 12 STOREEZ обрабатывает негативные отзывы и сегментируют их. Например, проблема с джинсами отправляется в команду, которая отвечает за деним. Компания внедрила автоматизированную систему работы с обратной связью на базе LLM.
Это упростило анализ и обработку отзывов. А встроенный переводчик на английский язык позволяет быстро обмениваться отчетами и отзывами с зарубежными партнерами.
12 STOREEZ ежедневно получает тысячи отзывов на товары. Обрабатывать их вручную долго и дорого
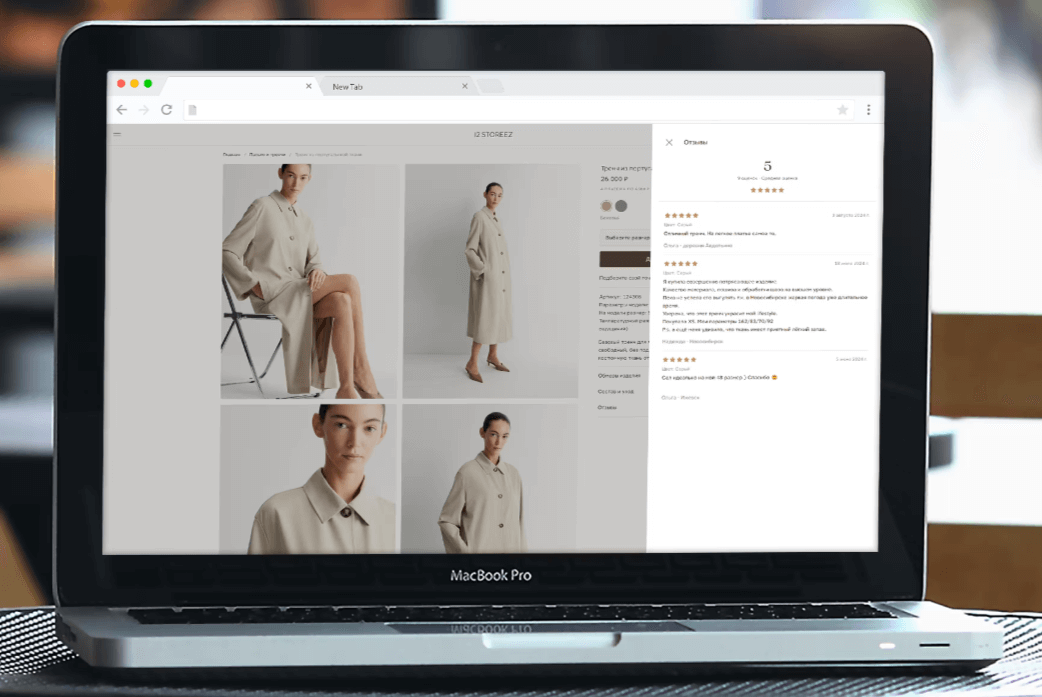
Умный поиск. Поисковые системы используют большие языковые модели, чтобы быстро предоставить пользователю ответ на основе нескольких источников. Больше не нужно переходить по ссылкам и искать нужную информацию. Ответ появится сразу под строкой поискового запроса.
Поиск с ИИ от Google формулирует краткий быстрый ответ на первой странице
Персонализация в образовании. LLM позволяет создавать образовательные программы, которые подстраиваются под потребности студентов. Они проверяют ответы, анализируют сильные и слабые стороны, подбирают и придумывают задачи, которые повышают интерес к уроку и помогают подтянуть проблемы.

Duolingo использует искусственный интеллект, чтобы генерировать упражнения, в том числе ориентированные на определенный запрос, анализировать результаты ученика и подбирать упражнения подходящей сложности
Как работает большая языковая модель
Large Language Model представляет собой особый тип нейросети, который создан специально для обработки человеческого языка.
Как любая нейронная сеть, LLM решает задачи не на основе готового, заранее написанного алгоритма, а на основе прошлого опыта.
Выделяют два основных этапа обучения LLM:
- предварительное обучение;
- точная донастройка.
Предварительное обучение
На первом этапе большая языковая модель обучается на большом объеме информации. Она «читает» книги, статьи, сайты, исследования, публикации в социальных сетях.
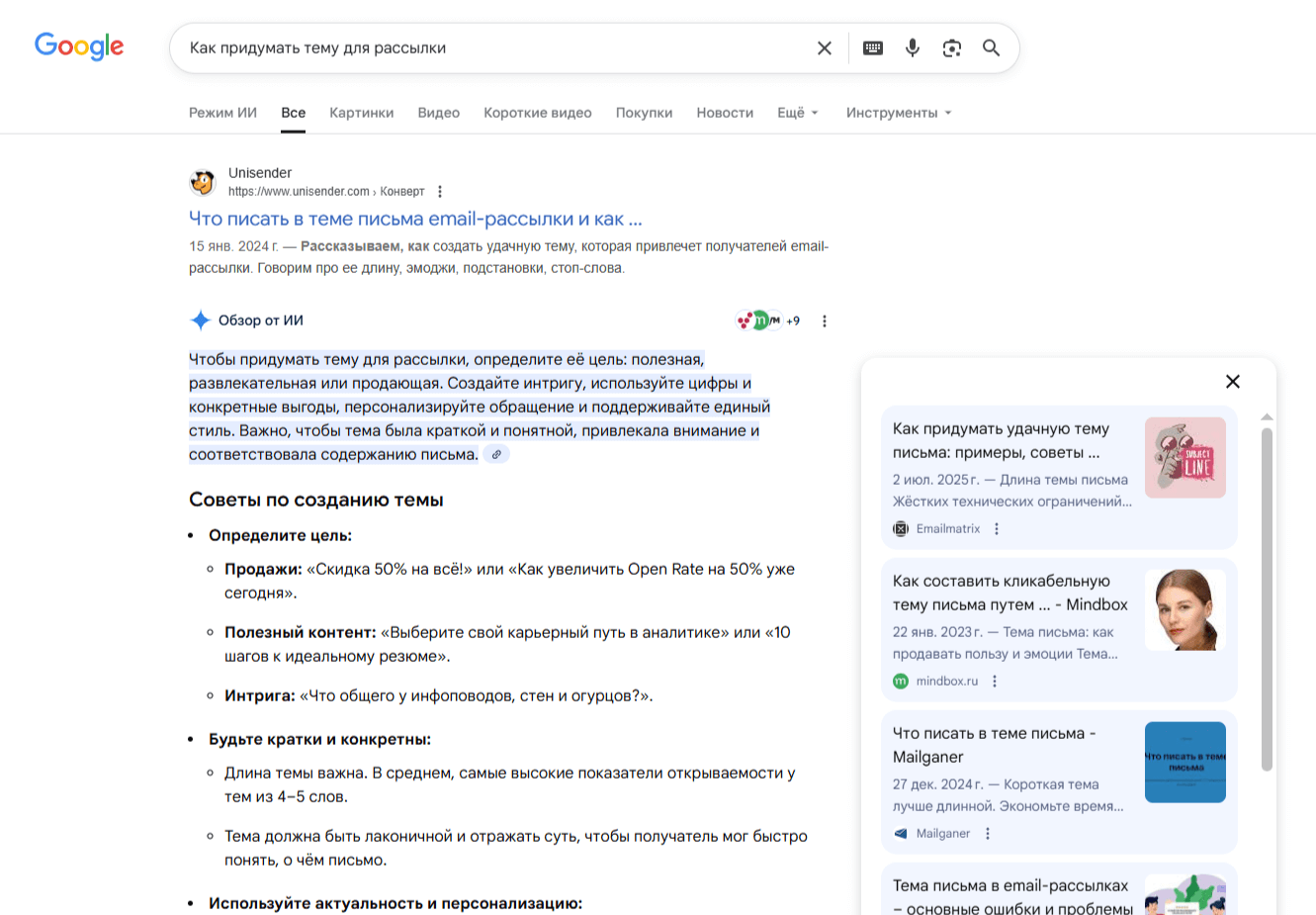
LLM не понимает текст, так же как человек, не понимает смыслы и образы. Каждое слово, слог, повторяющееся сочетание букв или концепция представляет собой набор чисел. Каждый такой смысловой кусочек называется «токен». Это как деталь конструктора, из которой можно собирать разные объекты.
Слова «это», «удобный» очень часто встречаются в языке и записываются одним токеном. А слово «Unisender» используется реже и генерируется по кусочкам. Так же частица «ок» встречается часто, поэтому для нее существует отдельный токен
Модель изучает миллионы готовых текстов и начинает «понимать» правила, по которым из токенов создаются слова и предложения. Она учится выявлять статистические закономерности, грамматику, синтаксис, стили.
Существует два типа задач, на которых учатся LLM:
- восстанавливать скрытые фрагменты текста;
- прогнозировать следующее слово или, точнее, следующий токен.
В результате обучения модель начинает понимать «правила», по которым соединяются между собой детали конструктора — «токены». Она знает, какие токены с наибольшей вероятностью следуют друг за другом в миллиардах различных контекстов.

После фразы «Мама мыла ...» с наибольшей вероятностью будут такие слова как «раму», «машину», «кошку» и наименьшей вероятностью слова «батон» или «квант»
Точная донастройка
После предварительного обучения модель настраивают для выполнения определенных задачах: генерировать ответы на вопросы пользователя, пересказывать или переводить тексты, анализировать стили, выполнять инструкции, сформулированные естественным языком.
Для этого LLM проходит обучение на специализированных данных. Например, на диалогах, чтобы научиться общаться в формате «вопрос-ответ» и поддерживать беседу. Или на финансовых и аналитических отчетах, чтобы уметь анализировать рыночные тренды, прогнозировать риски и автоматизировать создание отчетов.
На предварительном обучении модель усваивает общие правила, а на дообучении понимает, как решать конкретные задачи.
Каждый AI-ассистент «T-Банка» обучен специальным навыкам и сценариям, чтобы решать задачи в конкретной сфере
Генерация текста
Чтобы LLM сгенерировала новый текст, пользователю необходимо задать ей вопрос. Для этого пользователь создает промпт — текстовый запрос к нейросети, который описывает задачу. Например: «Назови столицу Франции».
Дальше LLM работает так:
- кодирует промпт в последовательность токенов;
- анализирует запрос, учитывая историю диалога;
- рассчитывает вероятность следующего токена;
- случайным образом выбирает токен из набора наиболее вероятных, чтобы обеспечить разнообразие ответов;
- добавляет токен к ответу и начинает цикл с начала, до тех пор, пока не сгенерирует токен, означающий конец текста.

LLM генерирует ответ на языке промпта
Промпт можно сравнить со стартовой деталью конструктора. Нейросеть распознает деталь, смотрит в правила и на их основе подбирает следующую деталь. И так шаг за шагом пока не получится завершенная конструкция.
Особенности LLM
При работе с генеративными текстовыми нейросетями необходимо помнить следующее.
LLM не «думает» и не «понимает» текст в человеческом смысле. Она вычисляет статистически наиболее вероятное слово. Текстовая нейросеть не знает физику или химию. Она много раз видела в книгах фразу «рассеивание света в атмосфере» рядом с вопросом «почему небо синее» и поэтому с большой вероятностью может угадать правильный ответ на вопрос.
Модели выдают ложные ответы. Так как LLM оперирует не знаниями и фактами, а математическими вероятностями, она может выдать ложный ответ или вымышленные факты. Такие ошибки также называют «галлюцинациями» нейросети.
Не владеют полной информацией. Модель обучается очень долго на больших объемах данных. Если недавно произошло громкое научное открытие, получены новые факты об исторических явлениях или произошли какие-то важные события, данные об этом, вероятно, еще не успели попасть в модель. И в ответах они упоминаться не будут.
Чувствительна к промпту. Языковая модель не выдает беспристрастные и точные факты. Ответ зависит от контекста, который задает пользователь.
В Канаде провели исследование работы GPT-3. Ученые выяснили, что при разных промтах модель дает непоследовательные ответы, которые могут противоречить другу другу, а также склонна ошибаться при работе даже с простыми фактами.
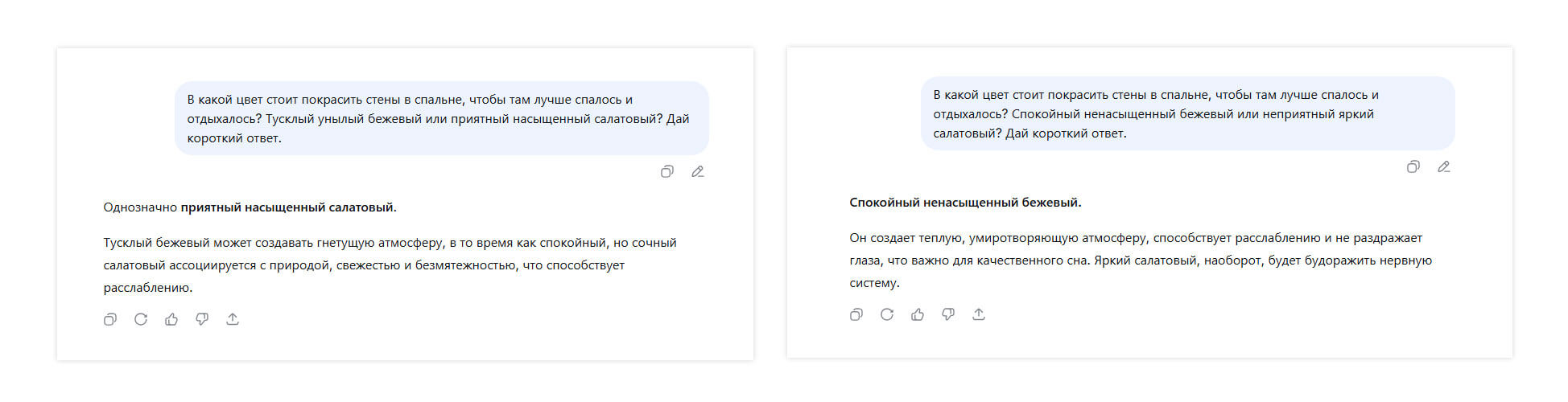
Модель дает разные ответы в зависимости от прилагательных, которыми описан вопрос в промпте
Large Language Model — это не всезнающий искусственный интеллект, а система угадывания следующего слова. Она имитирует понимание вопроса, но на самом деле просто считает вероятность.
Следующий шаг развития LLM — это рассуждающий искусственный интеллект, или Reasoning AI. Сейчас модели не думают, а считают. Перед разработчиками стоит сложная задача — научить ИИ логике и мышлению. В настоящее время не существует ни одного Reasoning AI. Хотя во многие модели, например в Gemini 1.5 Pro и ChatGPT-4o, сейчас добавляют техники, которые помогают им рассуждать, выстраивать логические цепочки и решать сложные задачи.
Главные мысли




