Всё для быстрого старта в email-маркетинге: блочный редактор, 200 шаблонов, ИИ-помощник. 1500 писем бесплатно.
Новости
16.06.2026
Wildberries запустил бренд-зоны для продавцов
Руководство с комментариями опытных сеошников

Семантическое ядро — список поисковых запросов, по которым пользователь может найти сайт. Его собирают для того чтобы понять интересы целевой аудитории, продумать структуру сайта и добавить ключи в текст.
В этом материале подробно разберемся с семантикой. В начале статьи будет теоретическая часть — что это такое, для чего нужно и когда сбор семантики лучше доверить специалисту. Во второй части будет пошаговая инструкция по сбору семантики. Если вам интересна именно эта часть — кликайте сразу: пошаговая инструкция как составить семантическое ядро.
Эта статья написана под надзором SEO-команды Unisender — благодарим коллег за экспертные комментарии.
Семантическое ядро — набор слов, фраз и запросов, которые характеризуют сайт, услугу или страницу в интернете. Использование таких слов на сайте позволит нам попасть в выдачу поисковика, хотя у самой семантики функции шире — о них чуть ниже.
Например, для интернет-магазина, который продает головные уборы, в семантическое ядро будут входить слова «купить шапку», «купить кепку», «шляпы дешево», «все ли шапки одного размера» и так далее.
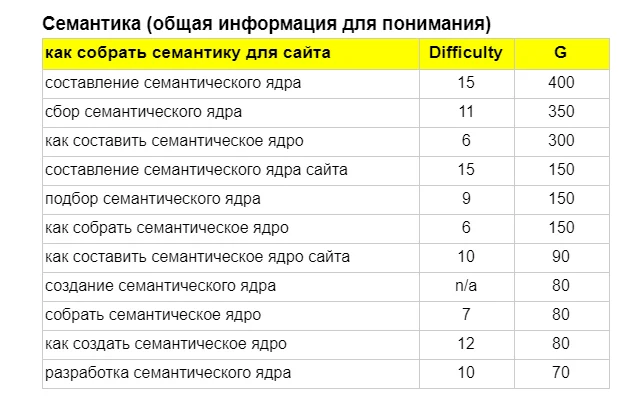
Вот основные причины:
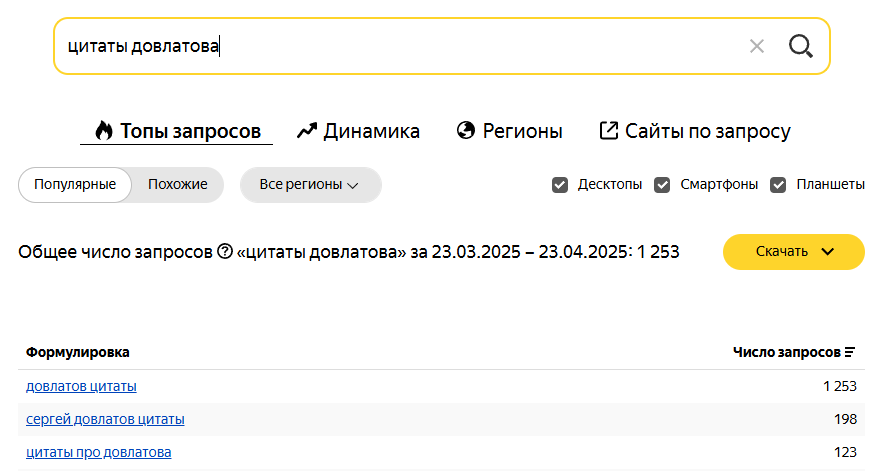
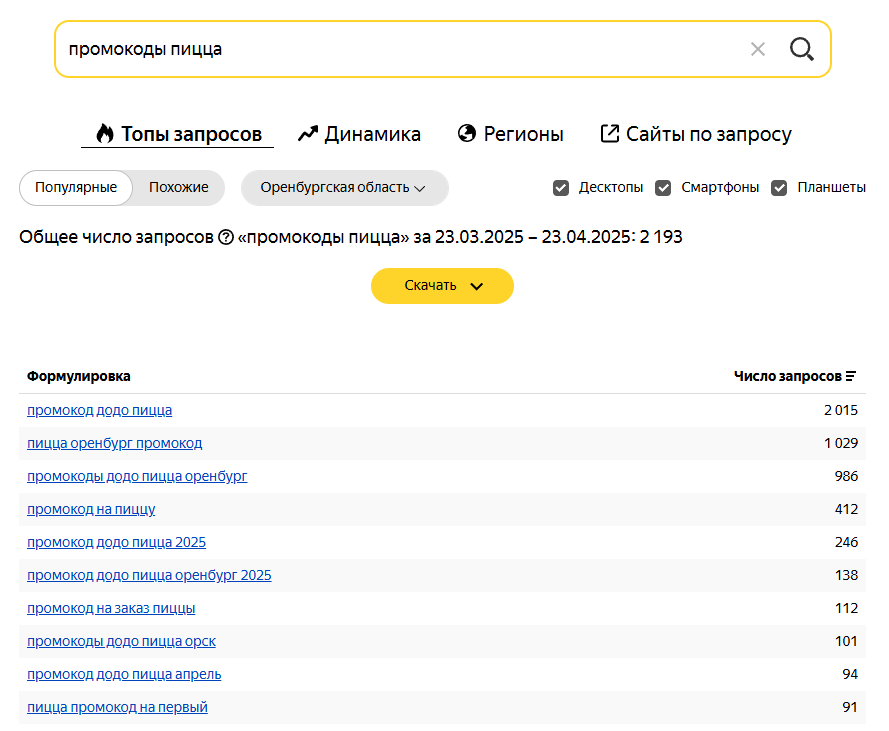
Исследовать интересы целевой аудитории. Анализ поисковых фраз — простой и достоверный способ узнать, как и что ищет человек: в поиске он не стесняется своих желаний. Более того, можно количественно отследить интерес людей к теме — в этом помогает частотность запросов в месяц:
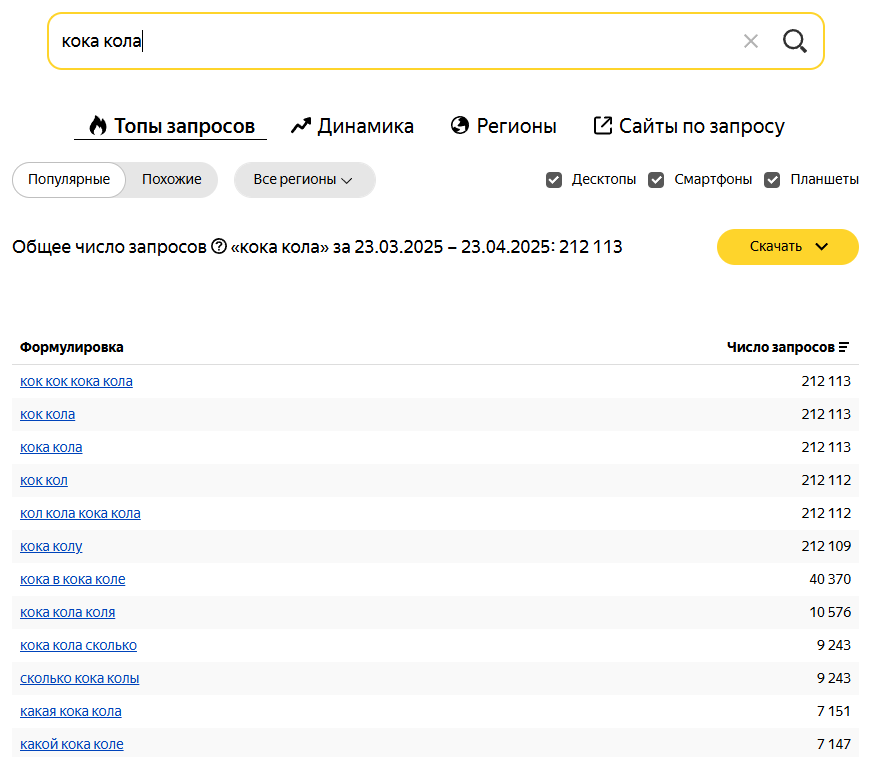
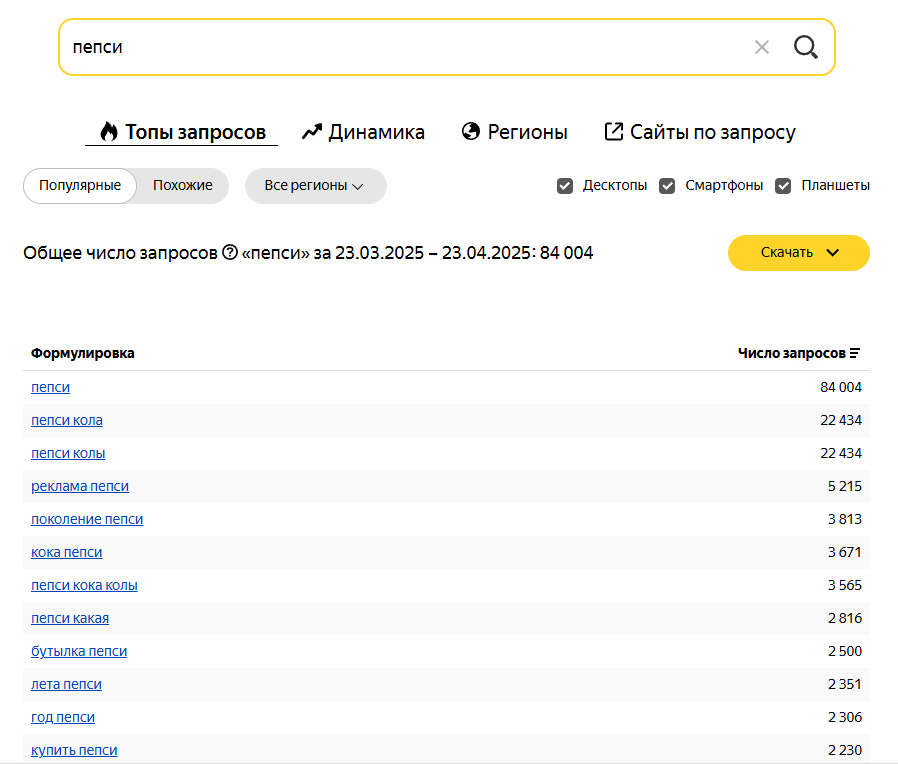
Анализ семантического ядра дает подсказки для развития бизнеса: закрыть непопулярные направления (их люди не ищут), открыть популярные — их часто ищут, а это потенциальный источник трафика и оплат.
Глобальная цель сбора семантики — понять, что хочет целевая аудитория, что ищут люди и как часто. Возможно, продукт который мы планируем выпустить или который уже есть, никому не нужен. В этом случае стоит сместить вектор развития в сторону популярных запросов.
Создать или доработать структуру сайта. Собранное семантическое ядро разбивается на кластеры. Кластер — группа запросов, которые поисковик считает одной темой и показывает по ней похожие результаты.
Кластер — готовая идея для страницы в интернете или статьи. Разбив семантическое ядро на кластеры, мы получим грубую структуру сайта, основанную на интересах аудитории. Следуя этой структуре, мы становимся клиентоориентированными.
Семантика — практически неисчерпаемый источник идей для статей. Причем не просто статей, а статей по темам, на которые есть спрос. В журнале «Конверт» больше половины всех статей SEO-оптимизированные. Эта статья — тоже.
Оптимизировать текст под поиск. На основе семантического ядра к страницам прописывают заголовок, метатеги, описание статьи, структуру с H2 и H3 подзаголовками. А сама семантика — промежуточный этап в формировании ключевых слов (ключей). А глобально все это нужно для пассивного продвижения сайта в поиске.
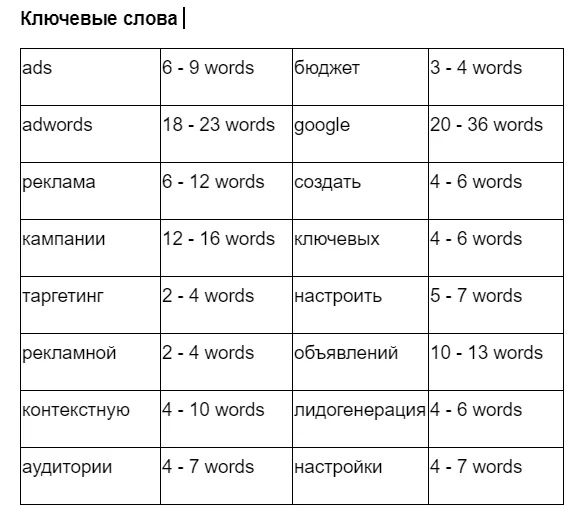
Подбор ключей — совсем другой процесс, в котором сеошник анализирует текст конкурентов в выдаче по определенному кластеру. Через SEO-сервисы можно оценить, какие ключи и в каком количестве используются в их статьях. Если целиться на ключи конкурентов из первых мест выдачи, есть шанс, что и наш материал тоже попадет в топ.
Этап подбора ключей возможен только после составления семантического ядра и кластеризации — благодаря им, мы ищем конкурентов.
Отслеживать динамику страниц в поисковике. После того, как собрано семантическое ядро, мы можем следить за движением сайта в выдаче по определенным запросам. Например, в семантику попал запрос «как поставить мат двумя конями в шахматах». Мы написали статью на эту тему и теперь следим, как поисковик ранжирует ее.
Сначала статья будет выше сотой страницы в интернете, потом постепенно будет подниматься до тех пор, пока не достигнет первой страницы и высших строчек — это показатель того, что SEO-стратегия работает. Если же сайт застрял дальше второй-третьей страницы выдачи, мы что-то делаем неправильно. Возможно, неправильно подобраны ключи или есть другие фундаментальные проблемы. Кстати говоря, на пустой доске мат двумя конями поставить невозможно 🙂
А еще может выясниться, что по другим запросам из кластера сайт продвигается медленнее. Это повод докрутить текст, добавить ключей, оптимизировать некоторые предложения под отстающий запрос.
Семантика — это еще не все
Сбор семантики относится к SEO — оптимизации сайта под поисковую выдачу. Чем сайт оптимизированнее, тем выше вероятность, что он окажется на первой странице по ключевому запросу. Соответственно, тем больше переходов на сайт и целевых действий.
Кроме того, органика (люди, которые перешли на сайт по запросу из поисковика) бесплатна и пассивно приносит людей годами. Например, нашу статью про сокращаторы ссылок за полтора года прочитали 120 000 человек. При этом мы не вкладывали денег в продвижение — просто правильно оптимизировали текст под поиск.
Сбор семантики — это только маленькая часть работы по SEO. На позицию сайта влияют его быстродействие, гигиена страниц, внешняя оптимизация, текстовая оптимизация и активность пользователей. Про все это подробнее можно почитать в нашем гиде по SEO. Если вы плохо ориентируетесь в поисковой оптимизации, рекомендую сначала изучить гид.
Составление семантики — не самый сложный в мире процесс, однако в нем легко запутаться (особенно без опыта):
Чем больше проект, тем выше вероятность ошибок.
Чем больше проект, тем больше нужд в специальном инструментарии
Есть специальные сервисы, например, Ahrefs, SEMrush и другие. Они достаточно сложные, и новичку в них будет сложно разобраться. В большом проекте может потребоваться сбор семантического ядра из 10 000 запросов (например, для крупного интернет-магазина) и развитая структура сайта с тысячами страниц.
Если ваш проект до 50 страниц, смело можете собирать семантику самостоятельно. Как минимум, это поможет определиться со структурой сайта и понять, на каких продуктах или услугах стоит сосредоточиться. А более тонкую работу можно оставить сеошнику, которого наймете позже.
Составление семантики — работа, и она требует времени. Если вы плохо с этим знакомы, то придется тратить время на изучение. Иногда целесообразнее сразу взять сеошника — пусть даже в рамках разового проекта.
Прежде чем собирать семантическое ядро, нужно синхронизироваться по некоторым терминам. Это теоретическая часть, чтобы лучше понимать инструкцию.
Частотность показывает количество запросов в месяц. Запросы в семантическом ядре разделяются на высокочастотные, среднечастотные и низкочастотные. Высокочастотные ищут чаще, чем низкочастотные, а среднечастотные — что-то промежуточное между ними. Деление запросов на эти группы относительное и зависит от сферы. В каких-то сферах 100 относится к низкочастотным, а в других — к высокочастотным.
Ранжирование — сортировка сайтов в выдаче в зависимости от их рейтинга, который подсчитывают алгоритмы поисковика. Чем выше рейтинг сайта, тем лучше он ранжируется — занимает верхние строчки выдачи.
На рейтинг влияют текстовая оптимизация, адаптивность, скорость загрузки, внешние ссылки и другие параметры. Запущенный сайт с идеальным семантическим ядром не попадет в топ — поэтому не фокусируйтесь лишь на одном сборе семантики.
Конкурентность запроса — величина, которая показывает сложность попасть в топ выдачи. Она зависит от конкурентов — чем их больше и чем качественные их сайты, тем сложнее будет идти продвижение.
Подробнее про конкурентность можно почитать здесь.
Опытные сеошники при сборе семантики указывают сложность (Difficulty). Если вы новичок — не парьтесь. Но если ваша ниша сильно конкурентная, опять же, нужен опытный сеошник.

Интент — это потребность пользователя, которую он хочет решить, когда вводит запрос. Некоторые запросы размыты, например, запрос «что такое осень» — пользователь хочет узнать, что такое осень или он ищет песню группы ДДТ?
Поисковики научились угадывать интент пользователя и даже по обобщенным запросам выдают нужное. И по запросу «что такое осень» все имеют в виду песню — это и показывает поисковик.
Учитывайте интент, иначе в ваше семантическое ядро попадут запросы, к которым вы не имеете отношения. Для этого просто внимательно просматривайте семантику на этапе чистки.
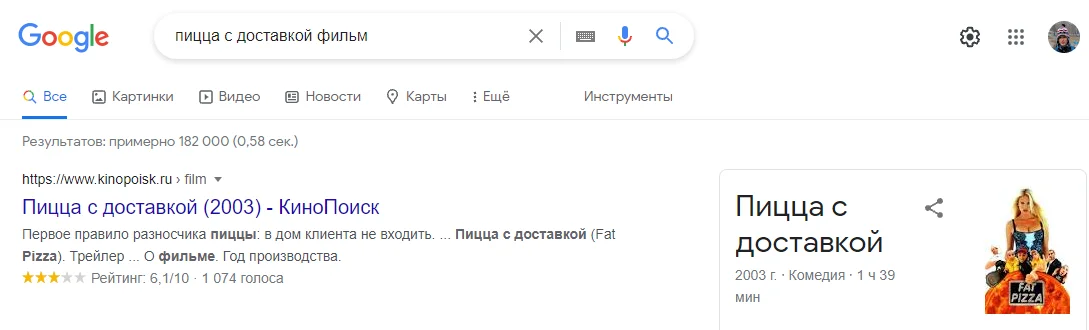
Геозависимость — фича поисковиков, чтобы адаптировать выдачу под место проживания пользователя. Если ввести «вкусно и точка адрес» — мне не покажут адреса фастфудов в Сыктывкаре, а покажут в моем городе.
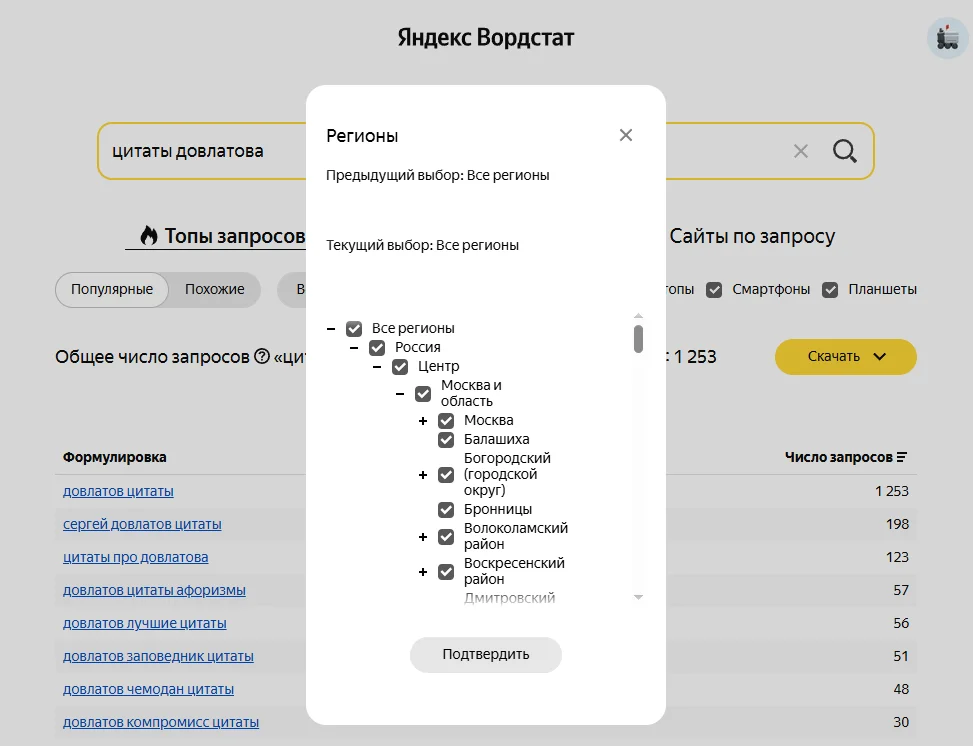
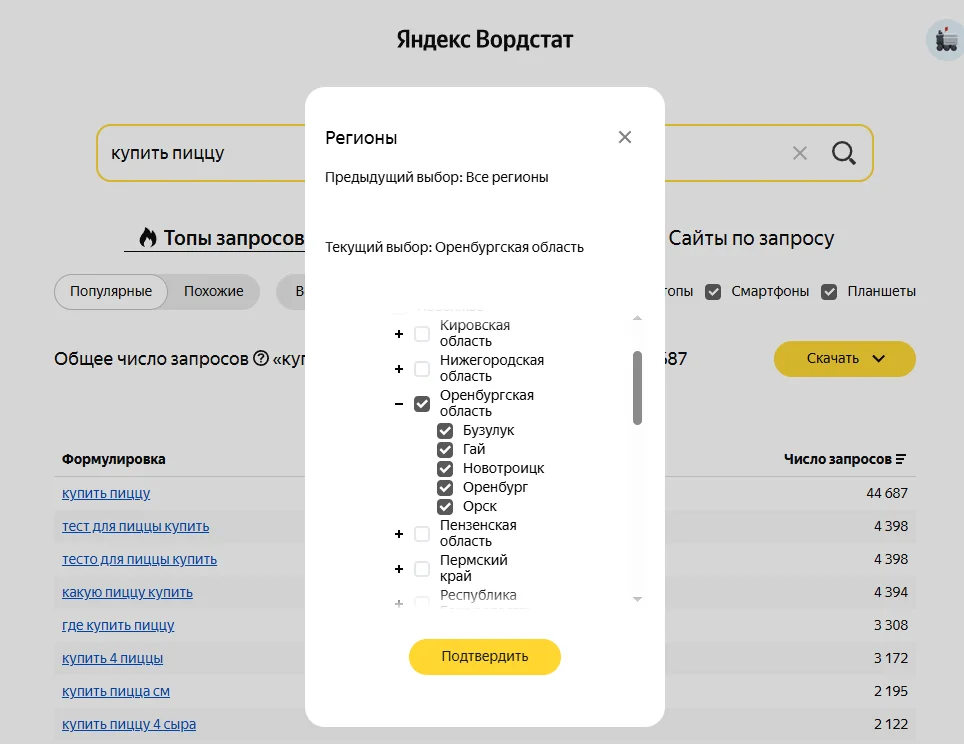
Если у вас локальный бизнес, семантику нужно составлять с учетом геозависимости. Для этого в Яндекс Вордстате есть настройка по региону — информация будет выводиться только по нему. А если у вас онлайн бизнес, то на геозависимость можно не обращать внимания — в Вордстате по умолчанию выбраны все регионы.
Пройдёмся по сбору семантики для сайта с самого начала.
Составление семантического ядра начинается с мозгового штурма. Ответьте на вопрос: если бы вы искали свой сайт в поисковике, то по каким запросам? Все идеи, которые придут в голову, записывайте в таблицу или текстовый документ.
Несколько советов, как охватить все интересные запросы:
Созвонитесь с командой, особенно с теми, кто участвует в разработке продукта и делает сайт. Попросите их ответить на вопрос выше. Записывайте все идеи и фразы, которые придут в голову.
Нужны запросы не только в рамках сайта в общем, но и в разрезе конкретных продуктов и частных вопросов клиентов. Например, сайт продает и устанавливает пластиковые окна. В семантику можно записать запросы «сколько стоит установка пластиковых окон» и «чем отличаются пластиковые окна». Такие запросы напрямую не связаны с нашими услугами, но все равно могут принести трафик, который позже конвертируется в клиентов.
Забавный источник идей — отдел продаж и служба поддержки. Им всегда задают кучу вопросов, и практически всегда эти вопросы популярны в поисковике.
Блог покроет информационные запросы и увеличит трафик на сайт
Даже если ваш сайт предполагается чисто коммерческим, мы все равно рекомендуем обратить внимание на информационные запросы, сделать под них специальные страницы или даже вынести в блог. Это в несколько раз ускорит продвижение и существенно увеличит трафик на сайт.
Блог ощутимо ест бюджет, особенно если организовывать собственную редакцию и налаживать регулярный выпуск материалов. Но это и не нужно — достаточно нескольких статей, которые бы отвечали на популярные запросы в поиске.
Производство статей можно отдать на аутсорс, а технически реализовать блог внутри домена — не сложно и не дорого. В таком случае это будет лишь единовременным вложением, а не ежемесячной статьей расходов.
Теперь покажу на примере, что у вас должно получиться на этом этапе. В моем примере я собираю семантику для интернет-магазина пиццы в Оренбурге. Я сгенерировал такие запросы:

Все запросы, которые мы получили на прошлом этапе, поочередно вбиваем в Яндекс Вордстат или Букварикс. Все сервисы интуитивно понятны, но про то, как пользоваться Вордстатом, у нас есть отдельная статья.
У Букварикс база Google и Яндекса, но я в нем не нашел функции фильтра по местности. У Яндекса это есть.
Покажу на примере, как работаю с Яндекс Вордстатом. Беру первый запрос из своего документа и ввожу его.
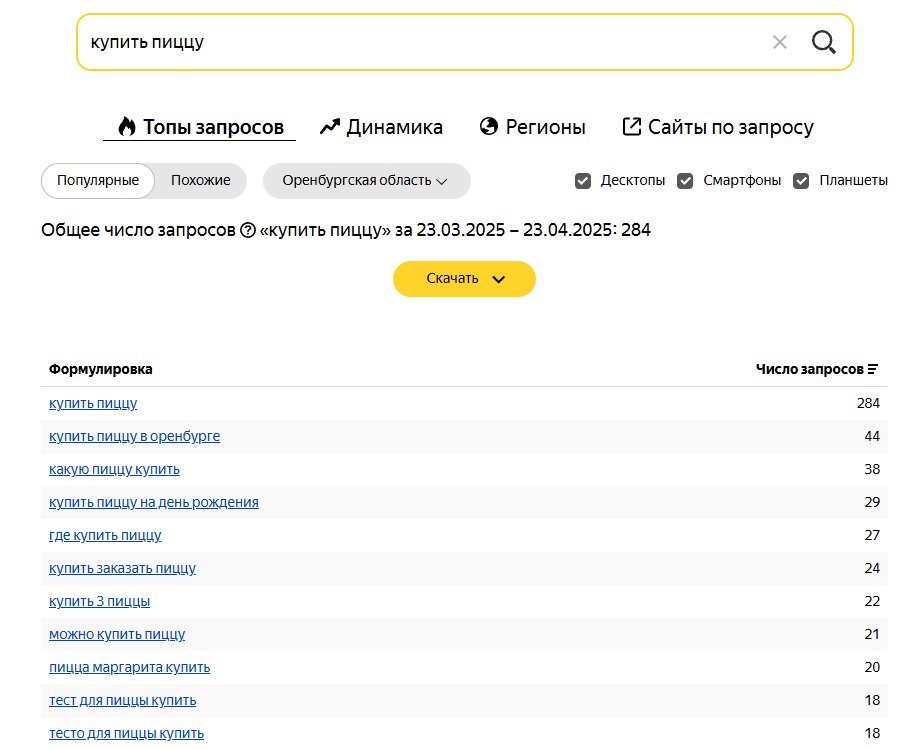
Настраиваю регион:
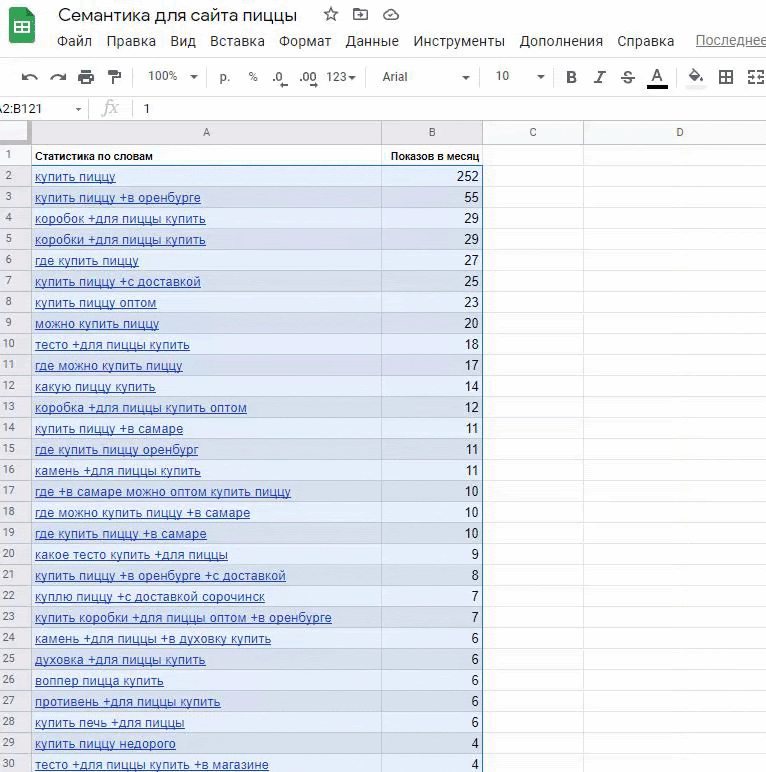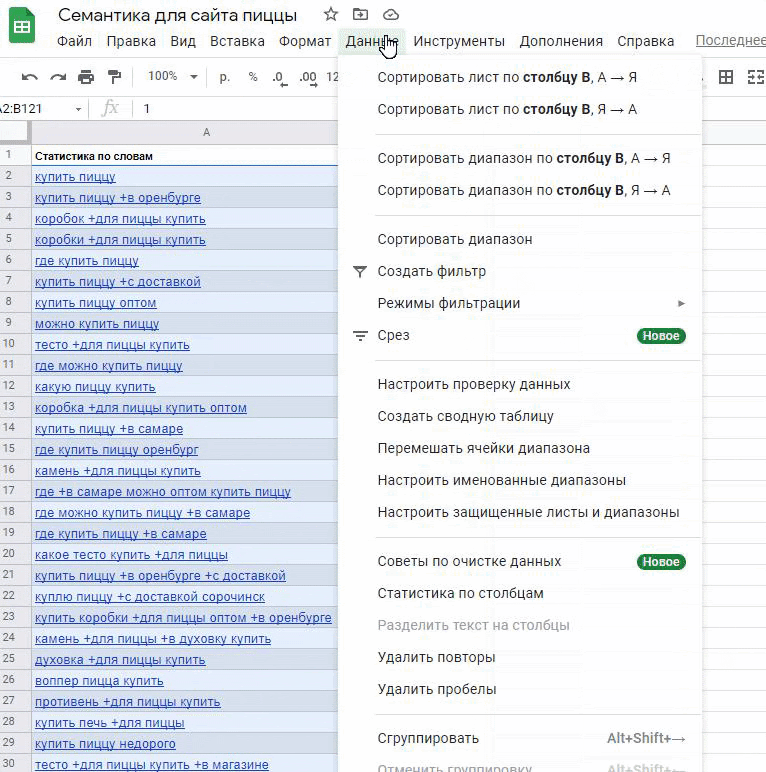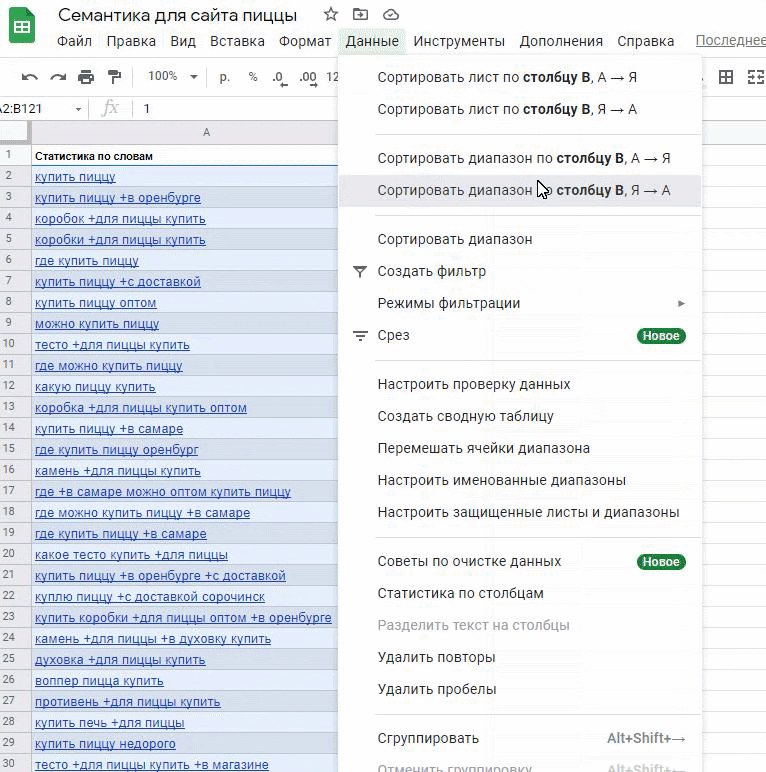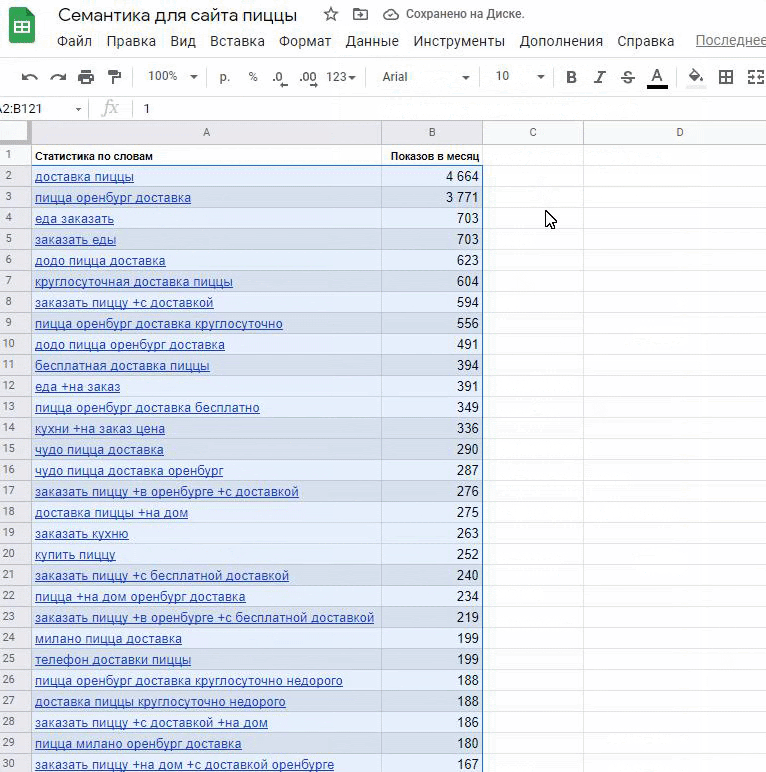
Затем всю статистику из обоих столбцов копирую в Google Таблицы.
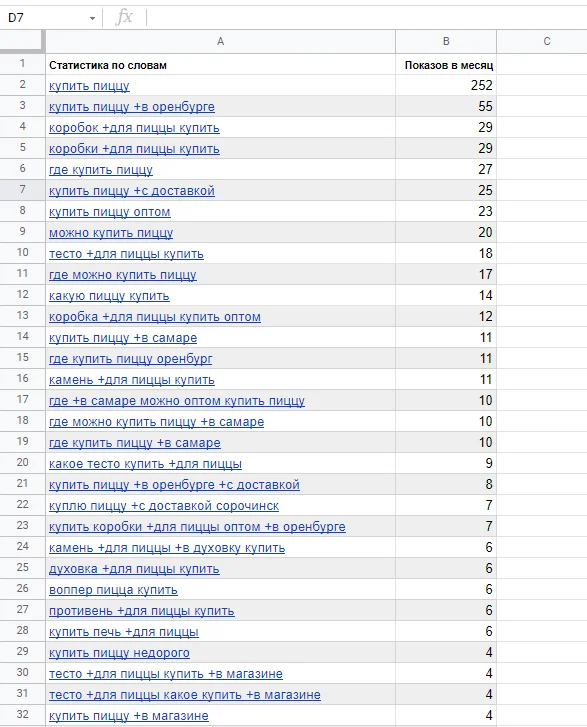
Располагайте запросы в один столбец. Пройдитесь по всем запросам из своего документа. Самые общие высокочастотные запросы пробейте дополнительно через Букварикс — в нем можно подсмотреть запросы, которые стоит поискать. Например:
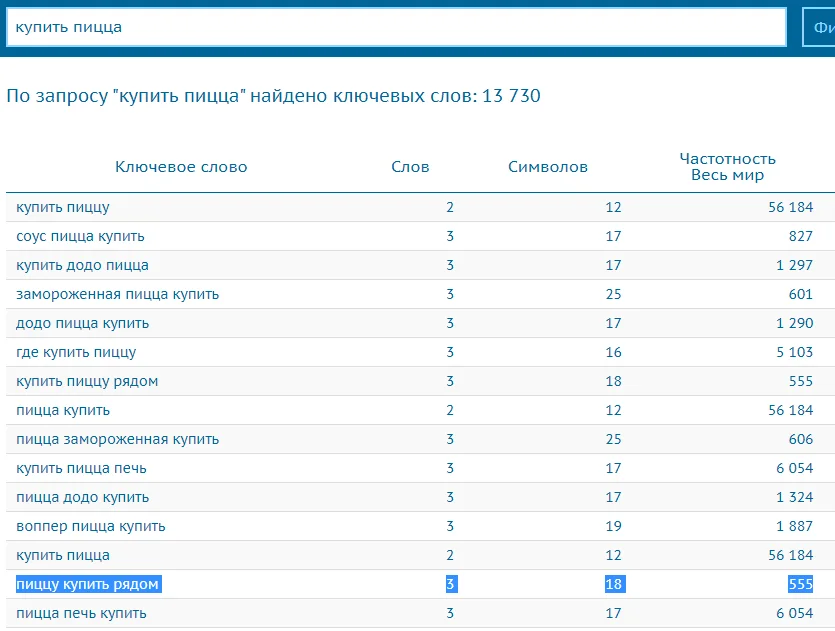
Важно в процессе подбора запросов не переусердствовать. В какой-то момент это утратит смысл — в таблицу будут попадать фразы-синонимы, странная низкочастотка и другой мусор. Соблюдайте баланс — если расслабитесь слишком рано, не дойдете до перспективных среднечастотных запросов.
Как понять, что пора заканчивать собирать семантическое ядро? Это вопрос опыта. Тут нет идеального правила. По идее, вы сами почувствуете, что уже перебираете одно и то же ,— это сигнал, что пора финишировать.
Многие сеошники, когда только начинают заниматься SEO, любят собрать тонну запросов и копаться в них. Потом понимаешь, что это бессмыслица. Пускай лучше запросов будет меньше для каждой страницы, но они будут качественные и понятные.
В интернете полно конкурентов — мы можем просканировать их через специальные сервисы и получить почти готовую семантику: важно отбирать только качественные страницы, которые высоко ранжируются в выдаче. Такие сервисы платные, и разбирать в статье их функционал мы не будем. Если интересно, присмотритесь к сервисам SEMRush, Ahrefs, Serpstat, или изучите нашу подборку:
20 сервисов для сбора семантического ядра
Но почерпнуть идеи у конкурентов можно и без специализированных сервисов. Заходите на их сайт и внимательно изучайте — пощелкайте страницы в интернете и посмотрите, что пишут. Вы, скорее всего, отыщете запрос, который стоило бы включить в семантическое ядро, но который сами упустили из виду — обращайте внимание на заголовки страниц.
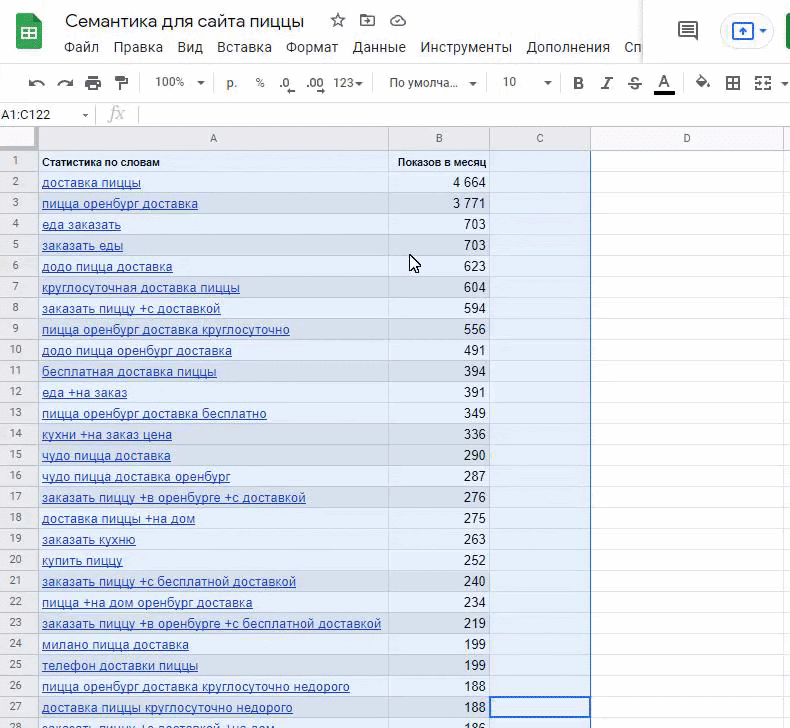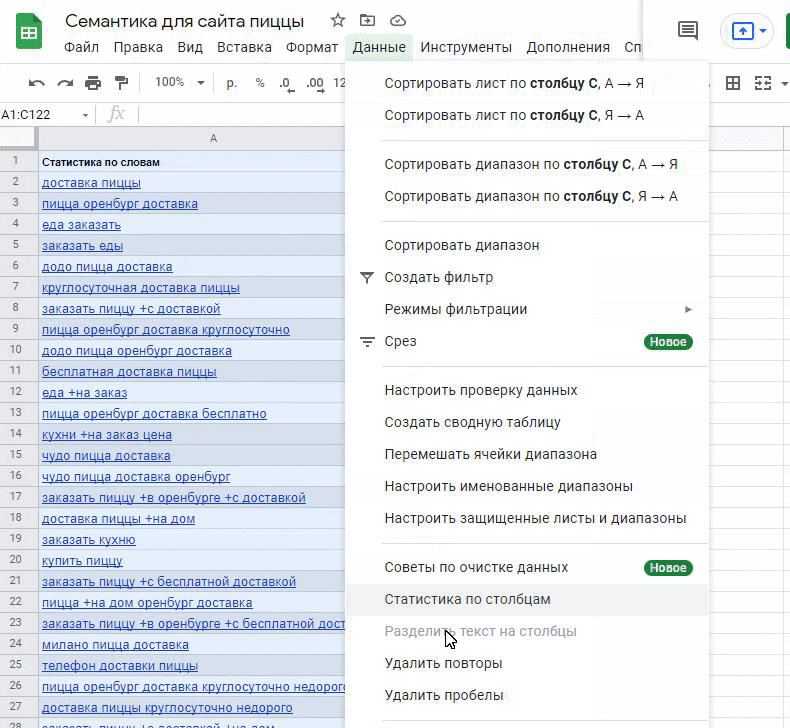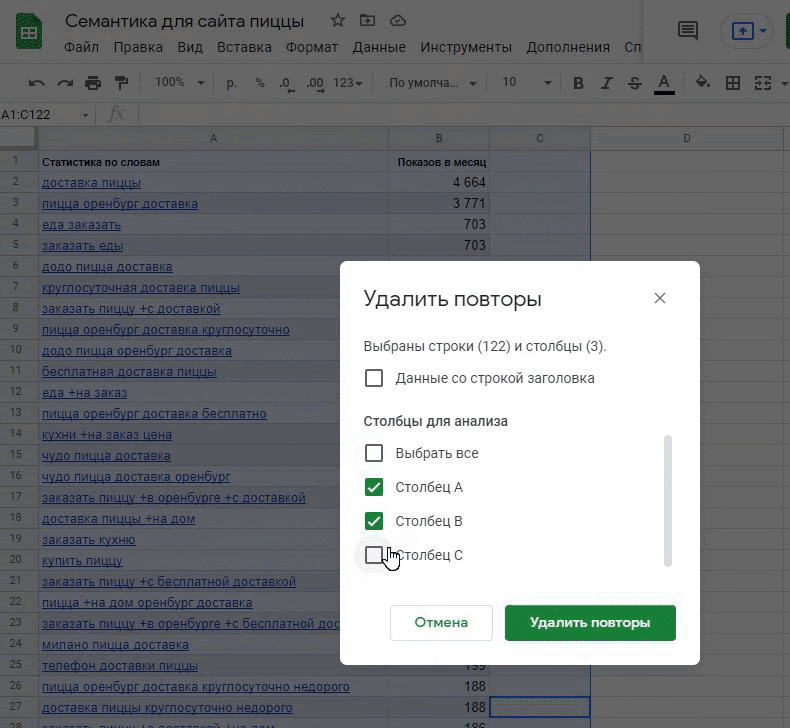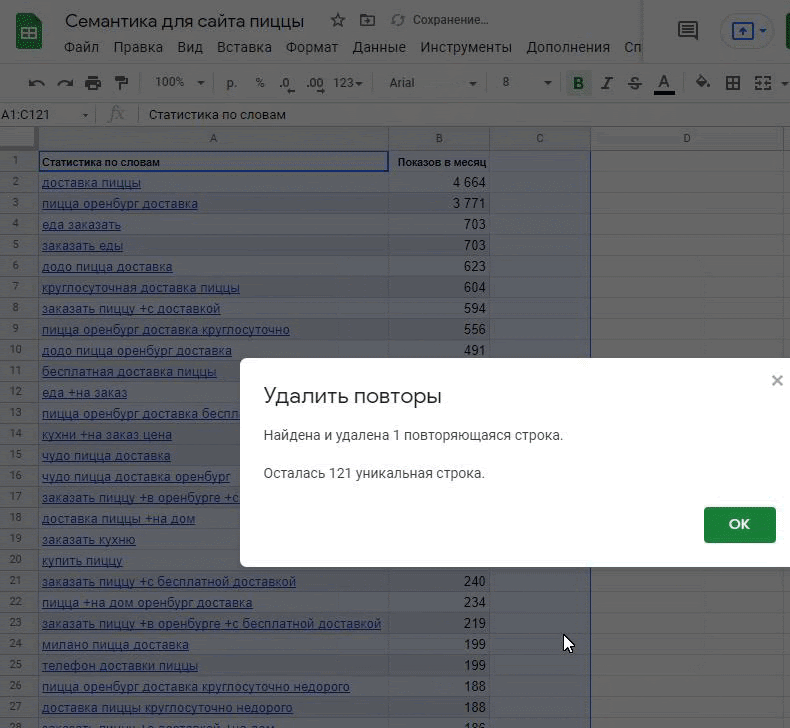
Удаление дубликатов. Некоторые запросы будут пересекаться. Нам они не нужны, поэтому удалим дубликаты через все тот же раздел «Данные»:
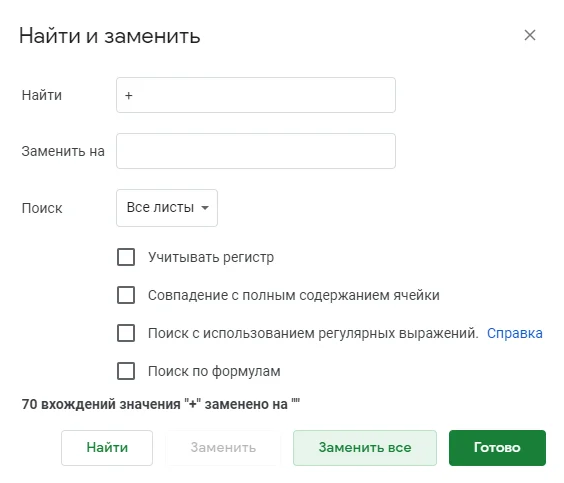
Удалить плюсы. Они будут мешать на этапе кластеризации.
Сортировка. Теперь всю таблицу отсортируем по убыванию частности. Отсортировать можно функционалом Google Таблиц. Этот шаг нужно повторить после следующего пункта «чистка нерелевантных запросов». При удалении запросов у нас появятся в случайных местах таблицы, а сортировка снова сведет всю семантику воедино.
В семантическое ядро так или иначе попадут нерелевантные запросы — такие запросы не характеризуют наш сайт, а люди, когда их вводят, ищут совсем другое. От таких запросов нужно избавляться — трафика они не принесут.
Удаляем такие запросы:
Давайте почистим ненужные ключи для нашего примера с пиццерией. Их получилось много:
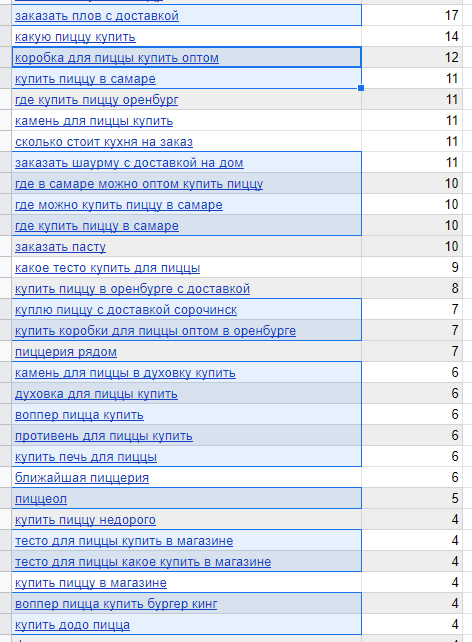
Плов и шаурму я не продаю. Печку, камень, противень, тесто и коробки для пиццы тоже. Воппер-пиццы нет в моем ассортименте. Удаляем.
Несмотря на то, что я смотрел запросы только по Оренбургу, в результаты Яндекс Вордстата подмешались левые запросы — пицца Сорочинск и Самара. Удаляем.
«Пиццеол» — непонятный запрос, который не прояснился даже после того, как я проверил в Google — удаляем. Еще на этот скриншот попала «Додо Пицца» — конкурент. Конкурентов, гораздо больше, все они выше. Конкурентов удаляем, либо переносим их в другой документ: если планируете запускать контекстную рекламу — там пригодится такая семантика.
Еще встретился запрос «чудо пицца». Я сначала не понял, а потом оказалось, что это местная пиццерия. Поэтому важно удалять запросы, которые вы не понимаете. Для верности можно загуглить их.
Несколько примеров с запросами под удаление. Они выделены синим:

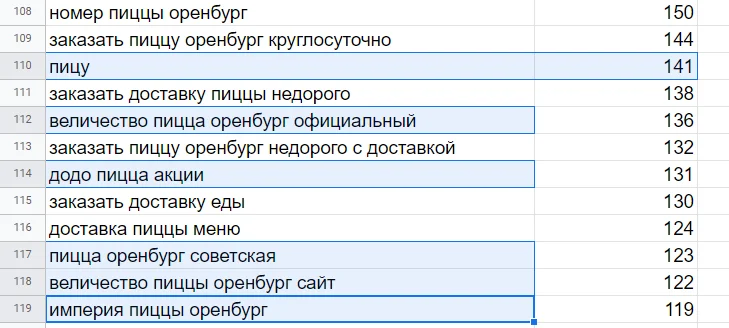

Если запрос перспективный, но у вас нет таких услуг — переносите его в скоринг-документ
При сборе семантики часто всплывают запросы, которые близки нашему бизнесу, но таких услуг у нас еще нет. Если эти запросы перспективны, и их часто ищут люди — не удаляйте их, а перенесите в скоринг-документ. Это документ с идеями развития и масштабирования бизнеса с точки зрения SEO.
В нашем примере про пиццу такие запросы — суши и роллы. Люди часто ищут их вместе с пиццей, но если мы занимаемся одной только пиццей — нам они не подходят.
Чистка — рутинный процесс, который может занять много времени. Проверять семантическое ядро нужно вручную, а иногда запросов много — больше тысячи. Ну тут ничего не поделать.
Не игнорируйте информационные запросы
При чистке важно сохранять осознанность и не делать это действие на автомате — можете пропустить интересные запросы, которые стоило бы внедрить.
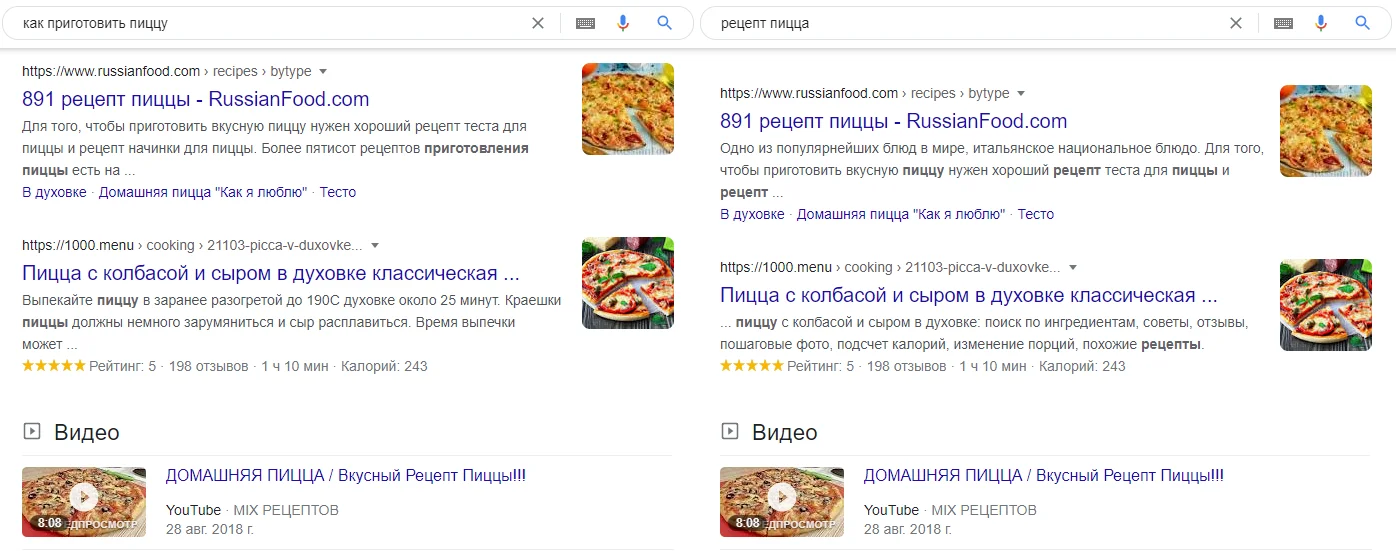
В примере про пиццерию мы выяснили, что люди часто ищут рецепты для пиццы — это информационный запрос. Пиццерия вполне может запустить небольшой блог, в котором будет раскрывать похожие темы. Так мы привлечем больше трафика и познакомим аудиторию со своим брендом. Бизнесу ведь нужно повышать узнаваемость — это один из инструментов.
Конечно, если человек ищет рецепт пиццы, он хочет сам ее приготовить, но в конце статьи мы можем предложить купить нашу пиццу, по рецепту, который искал пользователь. У человека уже появится лояльность к нашему бренду, а когда его пицца не получится, он закажет ее у нас 😁.
Другой интересный запрос, который мы увидели, — «рейтинг пиццерий». Мы можем на поддомене написать статью с рейтингом популярных оренбургских пиццерий. Похожую механику мы используем в Unisender: объективно сравниваем себя с конкурентами в статьях из базы знаний.
Если вы видите, что низкочастотные запросы повторяют основные запросы, только в них содержится странный хвост — их тоже можно удалять. В нашем примере про пиццу выяснилось, что все запросы с частотой 10 и меньше можно убрать — они так или иначе копируют запросы, которые уже есть.
Также удаляйте запросы-синонимы, в которых слова из запроса одни и те же, но в другой последовательности. Например, «пицца доставка» и «доставка пицца. Их можно искать вручную, но удобнее делать через программу Key Collector (платная) — там есть функция «анализ неявных дублей».
Ссылка на Google-таблицу с семантикой сайта пиццы
На этом сбор семантики закончен. Теперь ее нужно разбить на кластеры.
Напомню, кластеризация — деление семантического ядра на кластеры. Кластер — группа запросов, которую поисковик считает одной темой и выдает по ней пересекающиеся результаты.
Проверить кластеры можно вручную. В режиме инкогнито вбейте запросы и проверьте выдачу. Например, «заказать пиццу» и «купить пиццу» один кластер, выдача похожа.
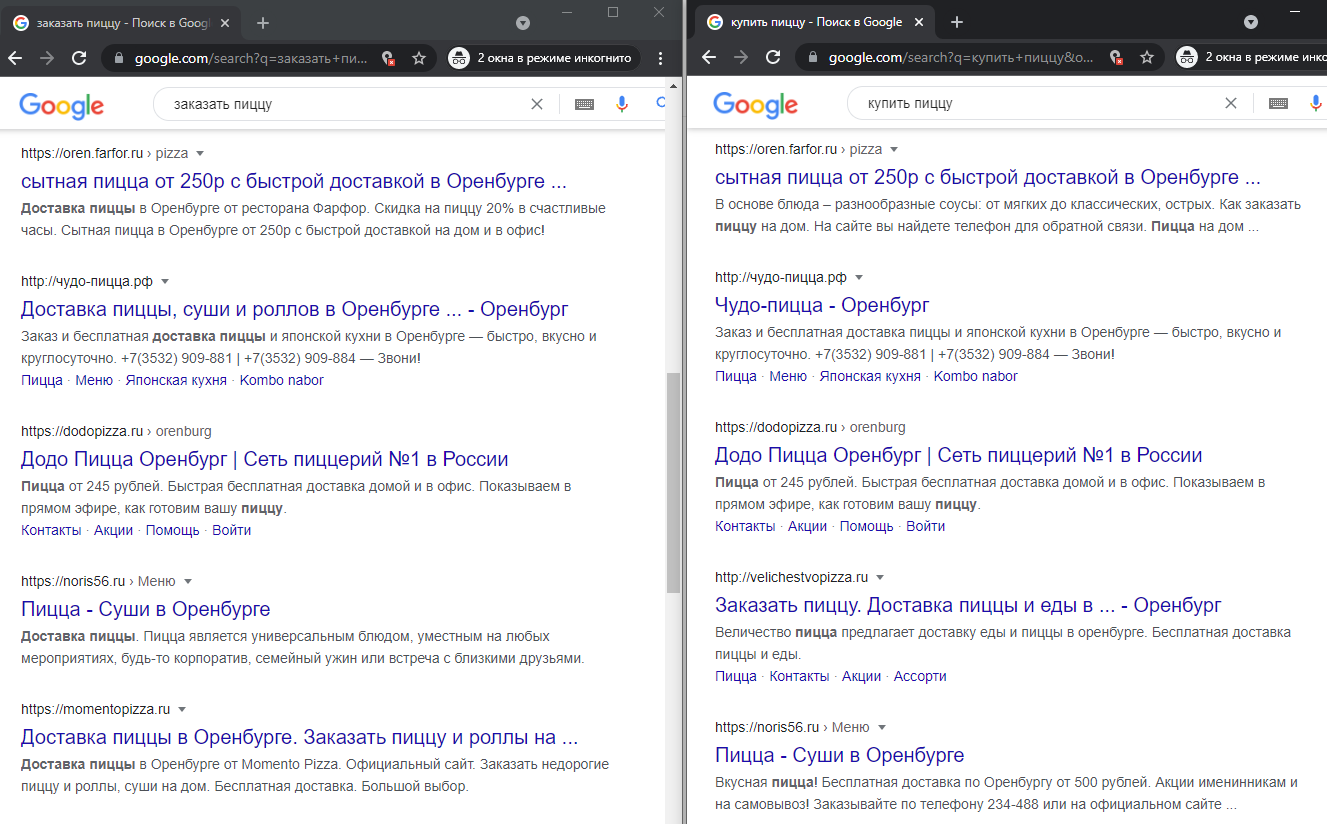
Проще всего кластеризовать семантику через специальные сервисы. Советуем KeyAssort — он платный, но с мощным функционалом. Еще можно присмотреться к KeyClusterer, этот уже бесплатный.
Далее будем кластеризовать семантическое ядро на примере KeyAssort. Принцип работы следующий: вы отдаете сервису свою семантику, он в зависимости от заданных параметров, проверяет пересечения, объединяет похожие запросы в кластеры и отдает вам. Вы можете посмотреть видео-инструкцию по работе с программой на официальном сайте, а я здесь кратко перескажу основные действия.
Приведенный ниже пример кластеризации — упрощенная схема. Более сложный и точный подход — когда мы берем частотность и сложность ключевого слова из платных сервисов.
Импорт. Чтобы программа все загрузила верно, лучше работать через шаблон. Скачать шаблон.
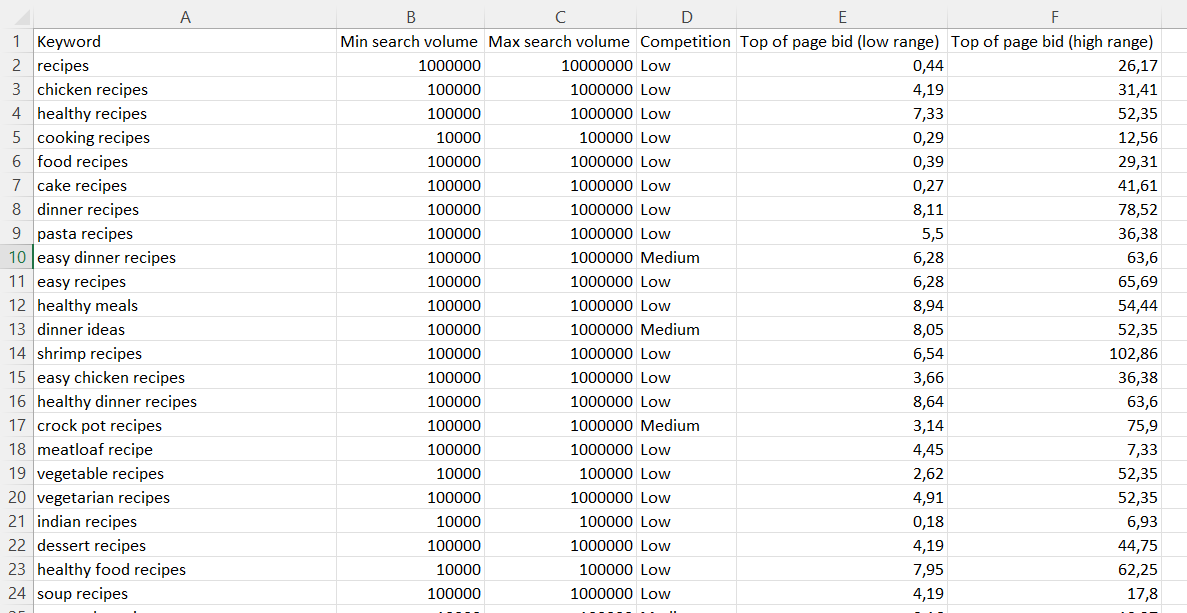
В первый столбец копируем запросы, а частотность копируем во второй и третий столбец (Mix search volume и Max search volume) — то есть их нужно продублировать. Поставьте значение «0» во всех остальных ячейках и «low» в Сompetition. Теперь импортируем:
Следующие окна оставляем без изменений:
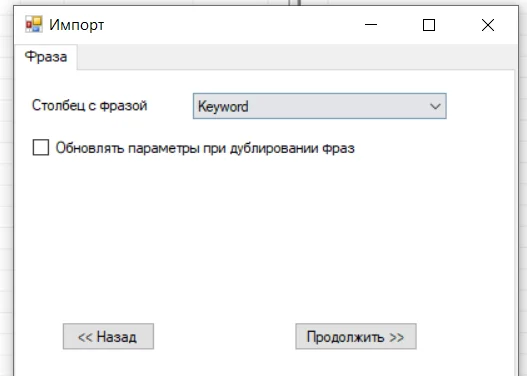
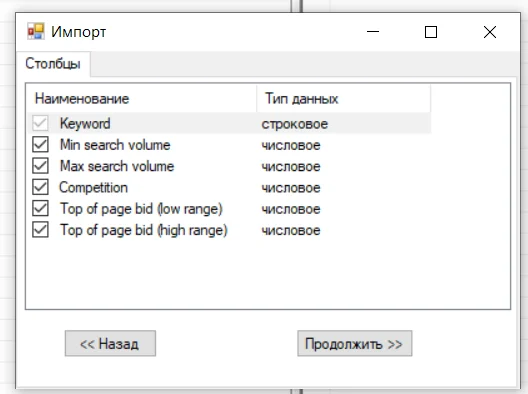
Получилось так:
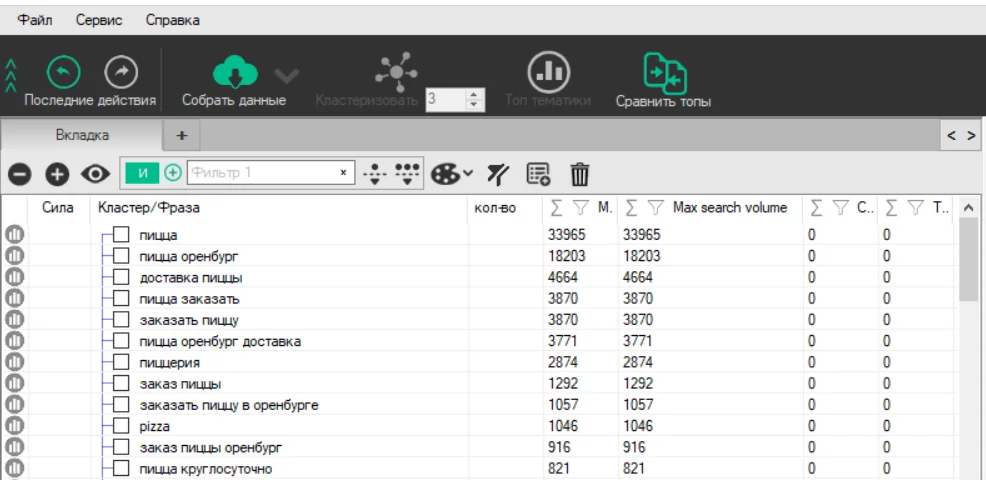
Сбор данных. Теперь нужно, чтобы программа проанализировала запросы и выявила среди них кластеры. Нажимаем «Собрать данные» в верхнем меню:
У нас около 200 запросов, и сбор данных займет несколько минут. Чем больше семантика — тем больше времени.
Кластеризация. Нажимаем в верхнем меню «Кластеризация» и начинаем эксперименты с настройками. Цель — получить адекватную сборку кластеров. Мы можем менять вид кластеризации, силу группировки и другие параметры — подробнее об этом читайте в справке KeyAssort.
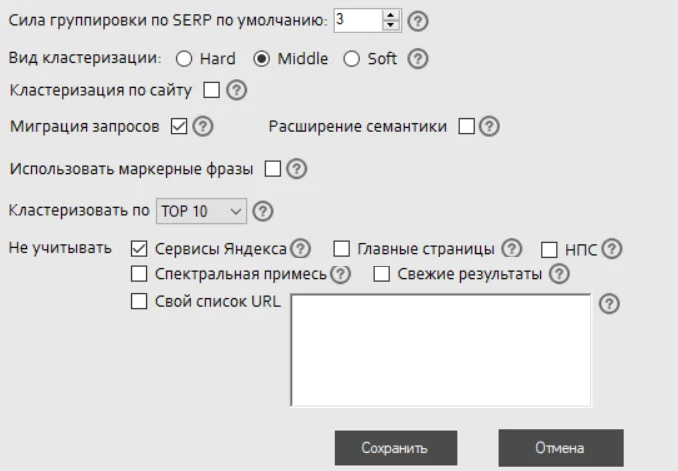
Меняйте настройки, пока не увидите адекватную сборку кластеров. Иногда приходится вручную перебрасывать запросы из одного кластера в другой, чтобы получить лучший результат.
В нашем примере получился такой результат:
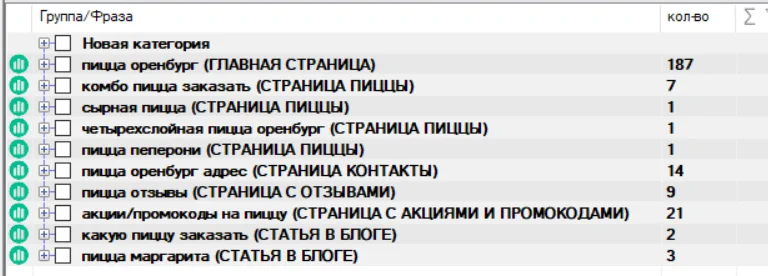
Структура будущего сайта получилась точной, но большая часть запросов попала на главную страницу — это особенность региональных проектов.
Теперь у нас есть собранная и кластеризованная семантика. Можно:
Статья получилась большой, пробежимся по основным выводам.
Что касается базовой теории:
1. Семантика — набор запросов и фраз, которые характеризуют наш сайт или конкретную страницу.
2. Семантика помогает продумать структуру сайта, отслеживать продвижение сайта по ключевым запросам в поиске, а также это необходимый этап перед формированием SEO-ключей. Собранное ядро — отличный советник по бизнес-идеям: на разработке каких продуктов и страниц, нужно сосредоточить внимание, а от каких наоборот отказаться.
3. Если у вас не очень крупный проект, есть желание и время погрузиться в SEO — собрать семантику можно самостоятельно. В остальных случаях нужен сеошник хотя бы на разовый проект.
4. Собранное семантическое ядро открывает путь к текстовой оптимизации страниц — добавлению SEO-ключей и метатегов, проработке структуры статьи, ее объема и другое. Это сложнее сбора семантики, и тут нужные более глубокие знания. Скорее всего, придется звать сеошника, и не факт, что его устроит собранная вами семантика.
Как собрать семантику за 6 шагов:
1. Обсудите с коллегами и сотрудниками, какие запросы характеризуют ваш сайт. Ответьте на вопрос: «если бы вы искали свой сайт в поисковике, то по каким запросам?»
2. Вбейте все фразы из предыдущего этапа в Яндекс Вордстат и скопируйте все предложенные запросы в Google Таблицы. Дополнительно используйте Букварикс.
3. Посмотрите конкурентов — изучите их разделы, вам наверняка придет идея, как расширить свою семантику.
4. Шлифовка и сортировка. Удаляем дубли, микрозапросы, символы «+» из выдачи Яндекс Вордстата.
5. Чистка. Удаляем непонятные фразы и все, что наш сайт дать пользователю не может. Перспективные запросы, но которые сейчас не описывают наши услуги, переносим в скоринг-документ.
6. Кластеризируем семантику через KeyClusterer.
SEO-продвижение не ограничивается одной лишь семантикой и текстовой оптимизацией — это более многогранный процесс, который охватывает работу с технической и контентной частью сайта. А еще желательно публиковаться на внешних ресурсах — блогах и каталогах. Подробности про всё SEO читайте в нашем гиде.
Всё для быстрого старта в email-маркетинге: блочный редактор, 200 шаблонов, ИИ-помощник. 1500 писем бесплатно.

 Почему четкая речь и уверенный голос стали новым soft skill в бизнесе, или Как развитие дикции влияет на карьеру
Почему четкая речь и уверенный голос стали новым soft skill в бизнесе, или Как развитие дикции влияет на карьеру
 Как работать с онлайн-документами без интернета
Как работать с онлайн-документами без интернета
 Теплые клиенты звонят в 3 раза чаще: как новый подход к рассылкам помог локальной организации улучшить маркетинговые показатели
Теплые клиенты звонят в 3 раза чаще: как новый подход к рассылкам помог локальной организации улучшить маркетинговые показатели
 8 лучших таск-трекеров для ведения проектов и работы в команде
8 лучших таск-трекеров для ведения проектов и работы в команде
Искренние письма о работе и жизни, эксклюзивные кейсы и интервью с экспертами диджитала.
Проверяйте почту — письмо придет в течение 5 минут (обычно мгновенно)